




Generative Adversarial Networks (GANs) are nothing but a framework for estimating generative models via an adversarial process.
As I told you before that the most common definition for GAN may be it connects the imaginary world to reality. Before going further let’s know when and how GAN was introduced as a reinforcement Deep Learning technique? A generative adversarial network (GAN) is a class of machine learning frameworks designed by Ian Goodfellow and his colleagues in 2014. Two neural networks contesting with each other in a game (in the form of a zero-sum game, where one agent’s gain is another agent’s loss).
This technique basically learns the pattern and statistics behind the training set. Using them the technique generates new data from given random noise with the same statistics as the training set. For example, a GAN trained on photographs can generate new photographs that aren’t completely real but look the same as the given images. These are capable of generating wisdom from garbage data. They can be used for generating images, videos, alter images, and much more! The recent research in GANs is focused on generating Deep Fakes (of humans) and detecting them.
STATISTICS BEHIND GAN
Probability
Probability is a measure of how likely an event is to occur. For example- Today there is a 60% chance of rain. There is a 50% chance of getting head in one toss. The odds of winning the lottery are a million to one. If an event is certain to happen, the probability of the event is 1. If an event doesn’t happen, the probability will be 0 and the probability never be negative.
Dependent and Independent Events
Two events are independent if the result of the second event is not affected by the result of the first event. Two events are dependent if the result of the first event affects the outcome of the second event so that the probability is changed.

Joint Probability
A joint probability is a statistical measure the calculates the likelihood of two events occ during together and at the same point in time. A joint probability is the probability of event Y occurring at the same time event X occurs.
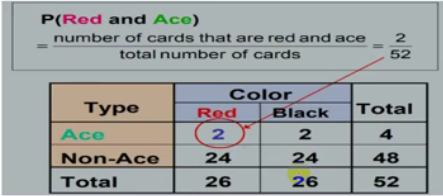
Conditional Probability
Conditional probability is defined as the likelihood of an event or outcome occurring, based on the occurrence of a previous event or outcome. Conditional probability is calculated by multiplying the probability of the preceding event by the updated probability of the succeeding, or conditional, event.
Bayes Theorem
Baye’s theorem, named after 18th-century British mathematician Thomas Bayes, is a mathematical formula for determining conditional probability. The theorem provides a way to revise existing predictions or theories given new or additional evidence.
Let A and B be two events with P(B) not equal to zero. The conditional probability of A given B is:
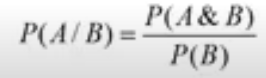
Generative v/s Discriminative Modeling
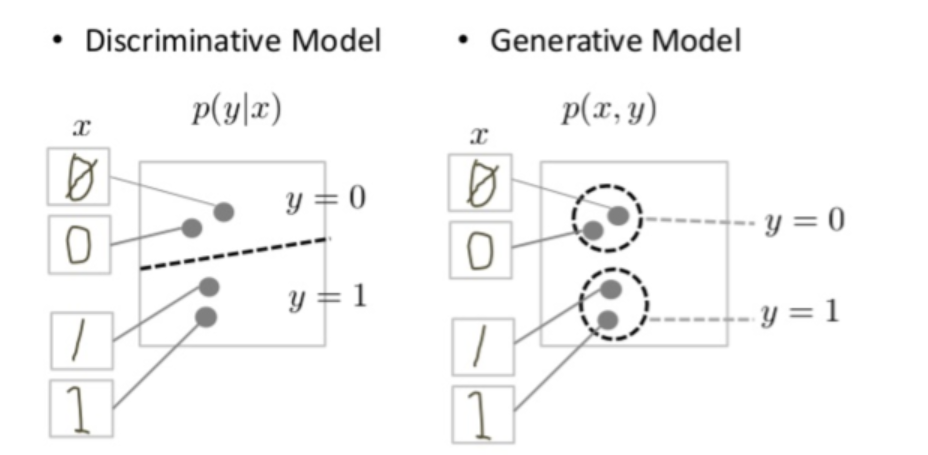
Generative Models
Generative models are models where the focus is the distribution of individual classes in a dataset and the learning algorithms tend to model the underlying patterns/distribution of the data points. These models use the intuition of joint probability in theory, creating instances where a given feature (x)/input and the desired output/label (y) exist at the same time.
Generative models use probability estimates and likelihood to model data points and distinguish between different class labels in a dataset. These models are capable of generating new data instances. However, they also have a major drawback. The presence of outliers affects these models to a significant extent.
Examples of generative models :
Naive Bayes Classifier
Hidden Markov Model
- Linear Discriminant Analysis
GANs too, are generative models. But unlike others, the novelty lies in its training evaluation measures, i.e. the adversaries.
Discriminative Models
Discriminative models, also called conditional models, tend to learn the boundary between classes/labels in a dataset. Unlike generative models, the goal here to find the decision boundary separating one class from another. So while a generative model will tend to model the joint probability of data points and is capable of creating new instances using probability estimates and maximum likelihood, discriminative models(just as in the literal meaning) separate classes by rather modeling the conditional probability and do not make any assumptions about the data point. They are also not capable of generating new data instances. Discriminative models have the advantage of being more robust to outliers, unlike generative models.
Examples of discriminative models :
Logistic Regression
Support Vector Machine
- Decision Trees
In GANs, discriminators introduce the ‘adversarial’ nature which we are about to discuss in the next section.
GAN, Architecture, and Working
Here, we discuss the actual architecture of GANs and see how it works.
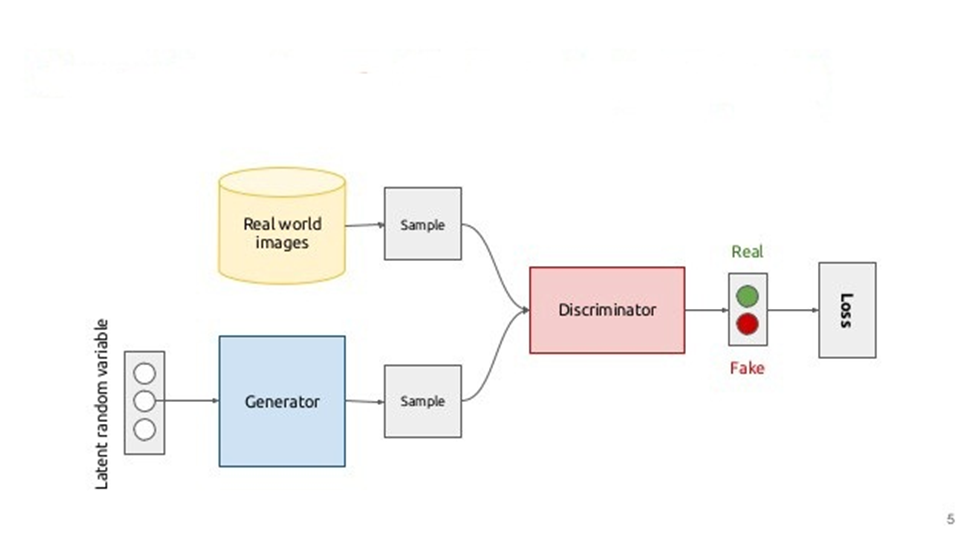
Here is the basic architecture of how GAN works and how the training goes on. We will discuss the architecture block by block. Let’s take the example of generating pictures of dogs through GAN.
Latent Random variables may be termed as noise. The data is from a random distribution. The data taken here will lead to the final desired pictures. Real-world images are those images whose are the ream images and data from the real distribution. This is the actual distribution. The goal of a GAN is to generate data belonging to this distribution from the noise mentioned in the earlier sub-section. In this case, we will take various real dog images. The purpose of the discriminator is to classify the image as real or fake. So, the discriminator can accurately be classifying the real images as real or fake images as fake. Again there will occur a backpropagation to reduce the noise and those who are classified as fake will go for a further generator process to train again. In our example, the discriminator can be a basic CNN-based binary image classifier.
The Discriminator is nothing but a trainable evaluation metric that tells how good/bad is the quality of the generated data.
The Generator is the main component of the GAN. In this part, the generative network attempts to learn the pattern, trends, and statistics of the distribution and generate data belonging to it.
Now I guess you will able to understand why it’s called two nets are competing. We will also discuss why it’s called where one agent’s gain is another agent’s loss in the mathematics part.
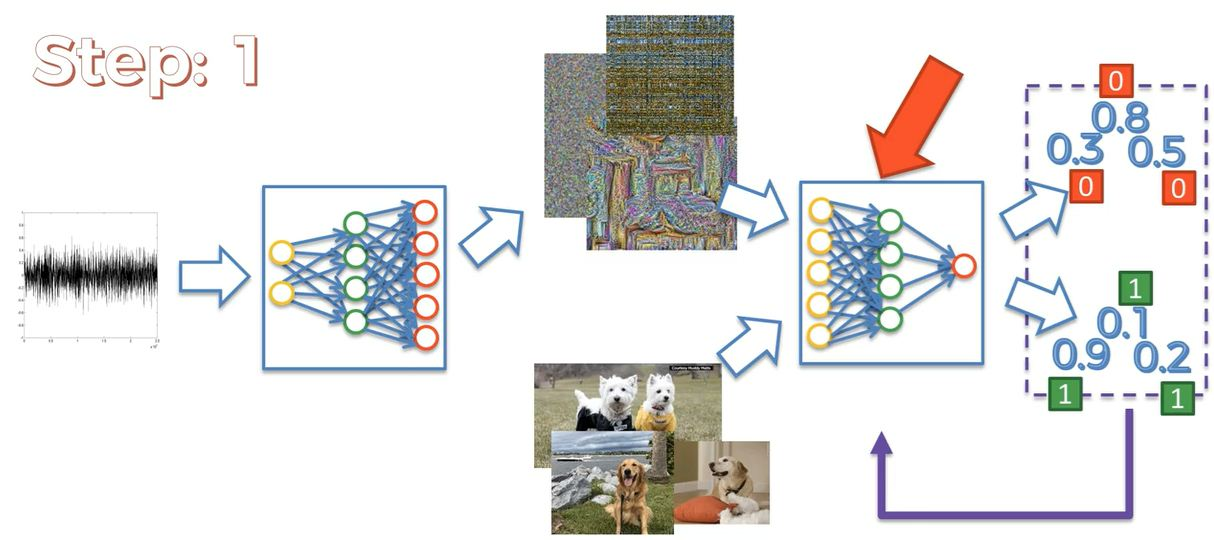
Here the training has started from taking noise from the random data to the generator and it trained on that data and now other real images are taken from real-world dog images and both images from real-world and generator will go to discriminator to get identified and classified as dogs images are real or fake.
In the first image now discriminator identified a dog and no dog as it’s shown above the probability values for being a dog. Thus, those samples will be backpropagated to the discriminator where the weights will get updated again till we get the probability value for being a dog only. Now in the second image, all the images will be calculated their probabilities according to being a dog but we need the probability value must be 1 for a dog. That’s why we backpropagated those samples that are having a probability of being a dog. In the second image, we don’t require samp-le real images because the discriminator has already aware of the trends and patterns to identify a dog.
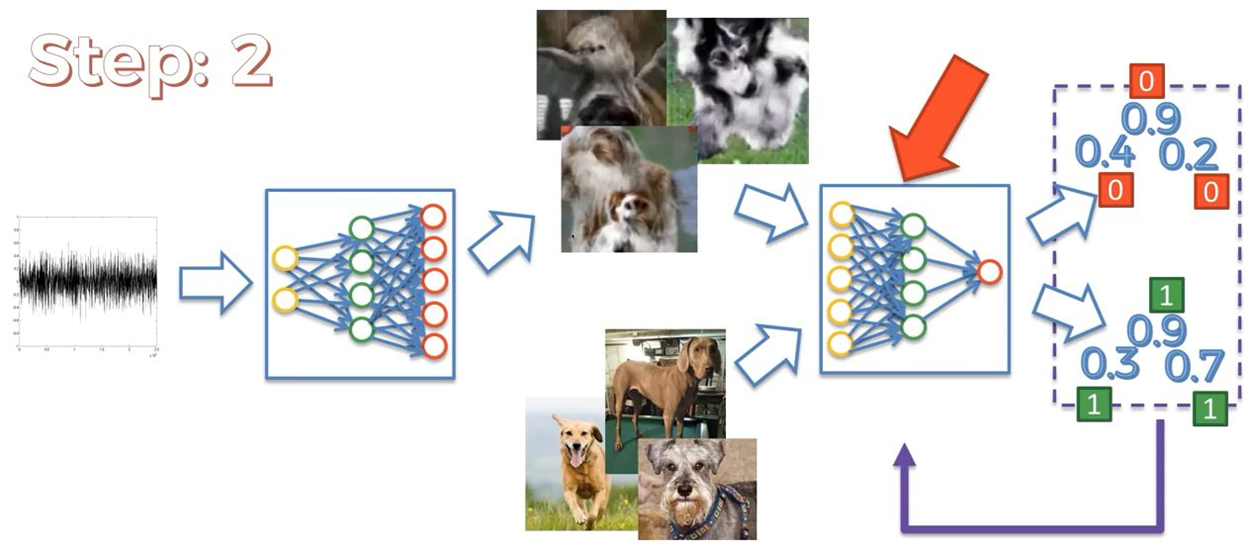
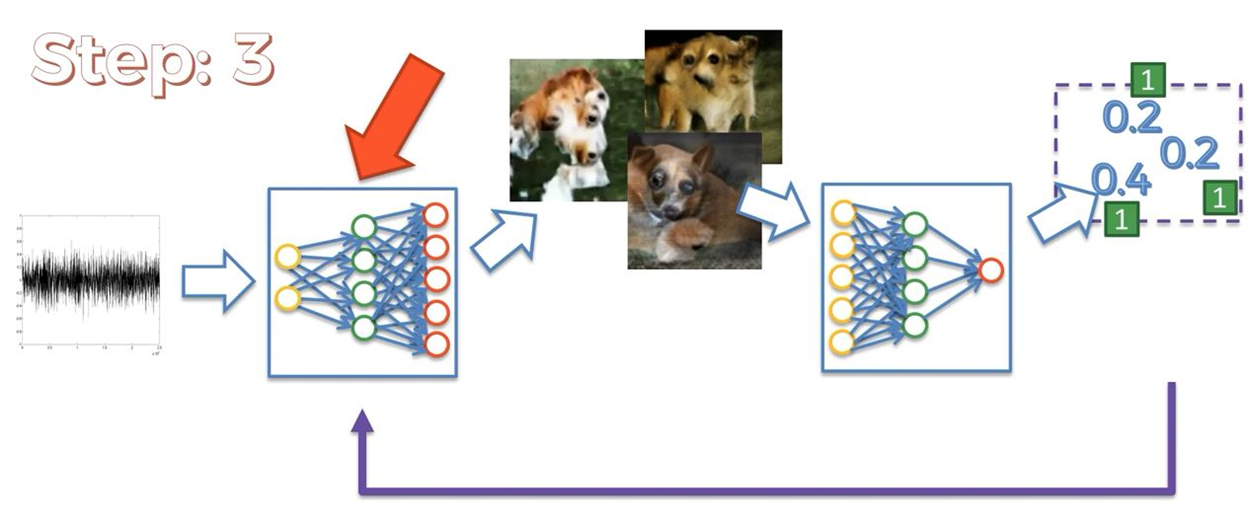
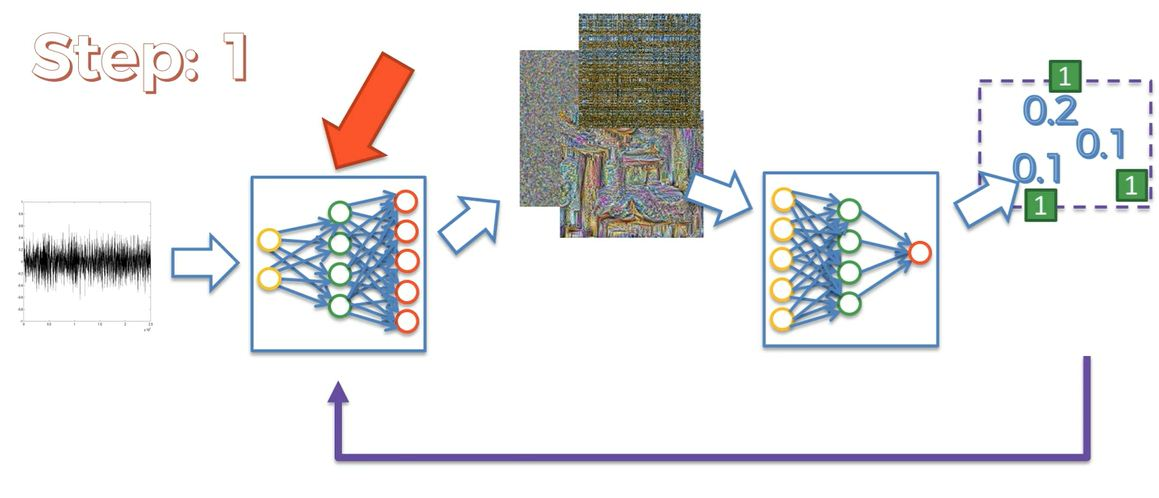
Here the same happens what I have explained above and we can see the random noise is getting a dog-like shape. While running the training process for lots of epochs our predicted and generated images will be getting more meaningful and the epoch will run until the loss is minimized.
Before going to the loss function I would like to discuss the difference between CNN and DCNN.
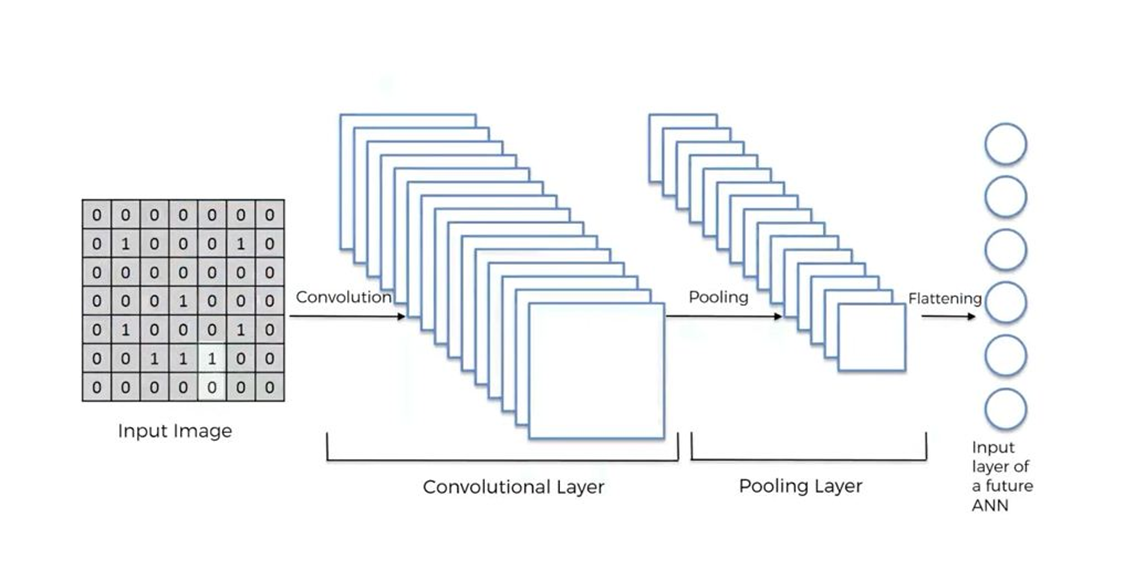
For detailed knowledge of CNN, you may refer to: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
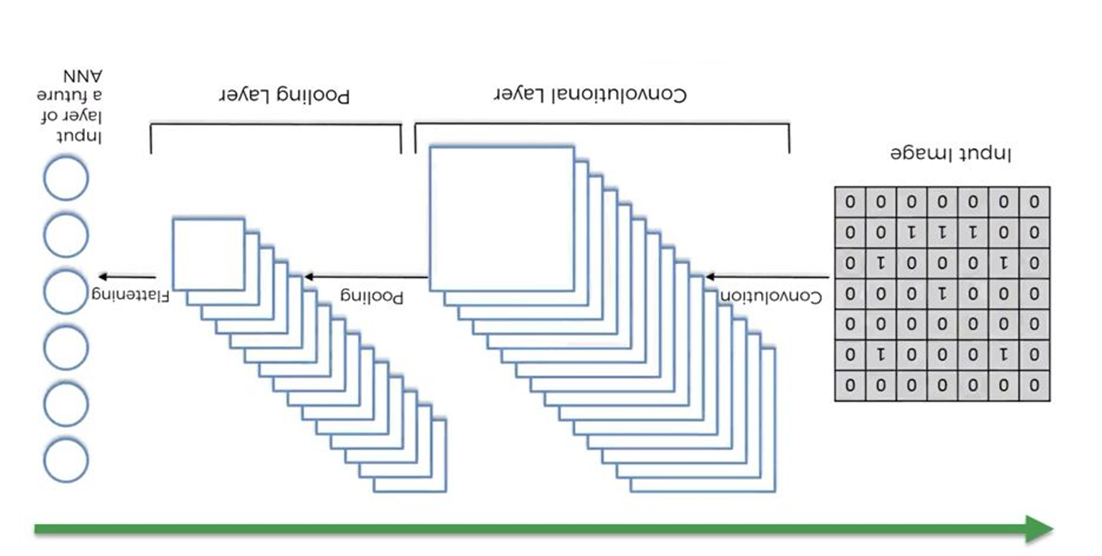
DCNN is also known as Deconvolutional Neural Network. Using simple words, CNN we input the image and it goes through convolution, pooling, and then flattening into a vector form for the training process. DCNN is the opposite of it and it can create an image from the flattened vector. It’s the reverse one.
For detailed knowledge of DCNN, You may refer to: https://searchenterpriseai.techtarget.com/definition/deconvolutional-networks-deconvolutional-neural-networks
Training Loss
The GANs paper defines the training loss as:

This is the Minmax loss, the discriminator tries to maximize it and the generator tries to minimize log(1 — D(G(z))) as it cannot touch log(D(x)).
However, the paper also suggests modifying this loss for the generator to maximize log(D(G(z))).
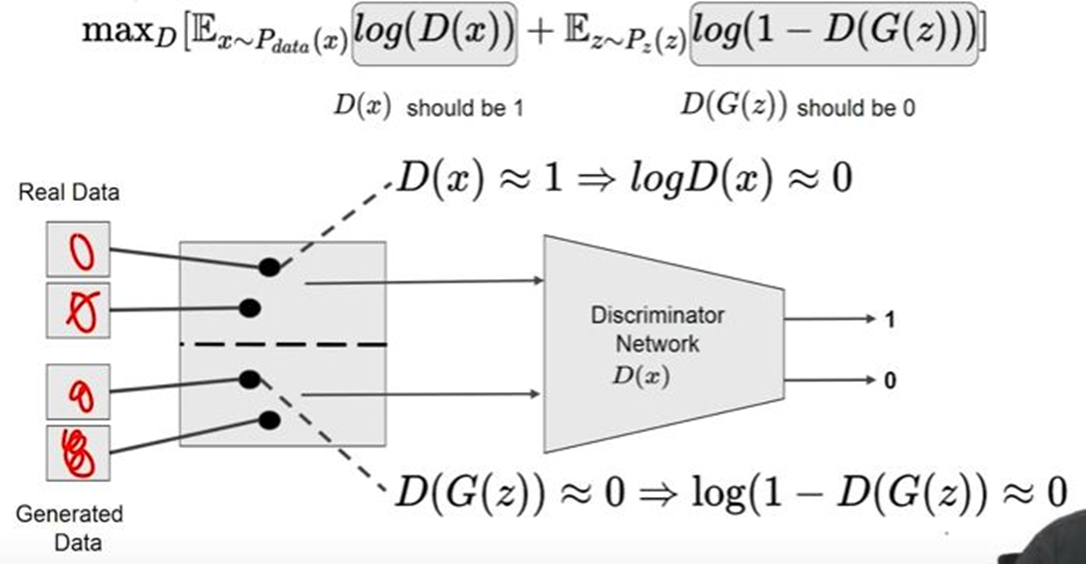
Here we get the intuition of why it’s called as to where one agent’s gain is another agent’s loss. Because at the same time discriminator tries to maximize the loss function and the generator tries to minimize the loss function.
Application of GAN

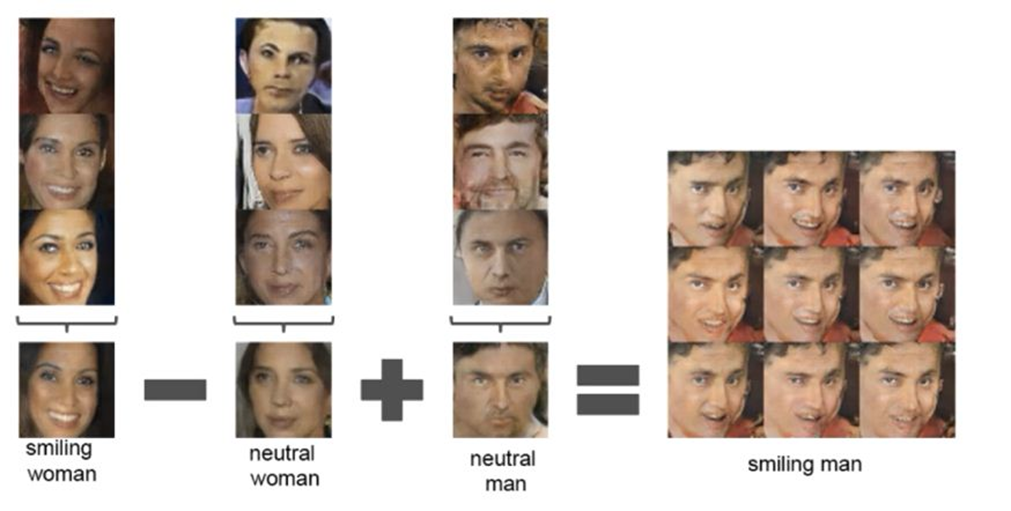


In this method, the clearest and resolution enhanced photo of a moon can be processed using lots of the moon’s real images.
- DeepFake Generation and Detection is one of the latest research topics in GANs which essentially generates edited or tampered images that look realistic to the naked eye. This can be easily done manually with the help of photo/video editing software and hence, is vulnerable to misuse. DeepFake detection can be derived as a corollary to generation.
Types of GAN:
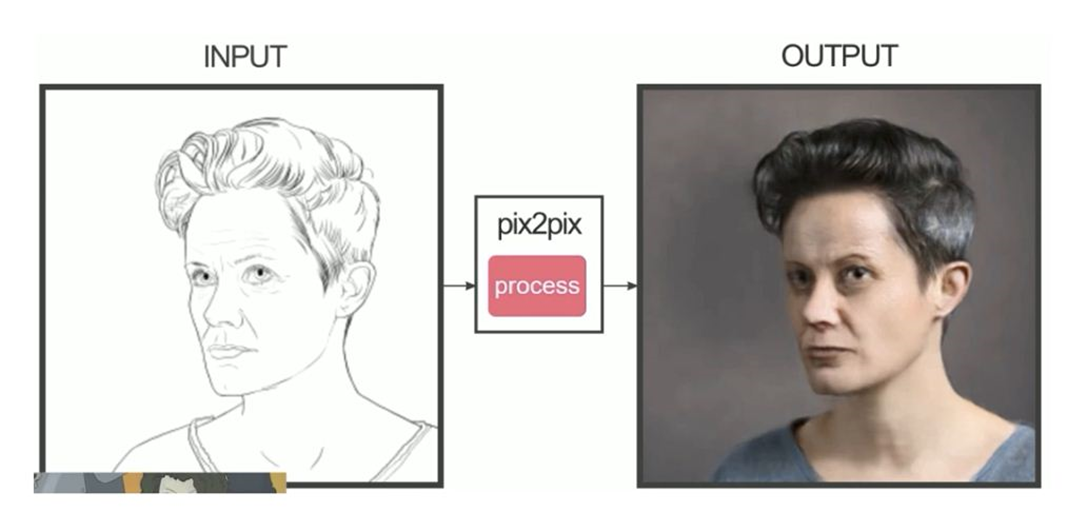
- Vanilla GAN
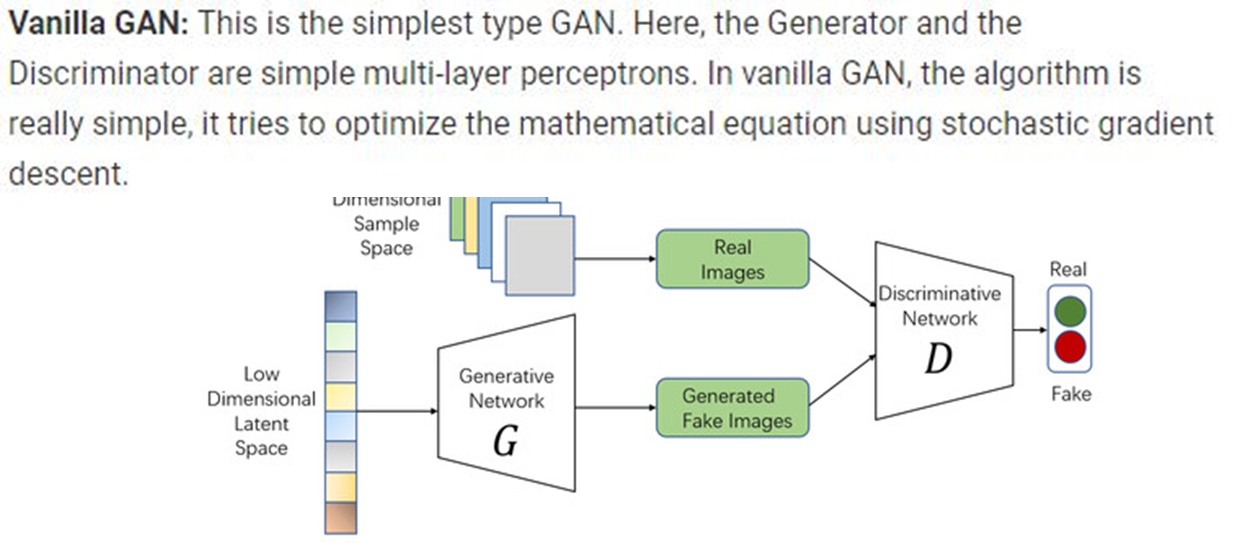
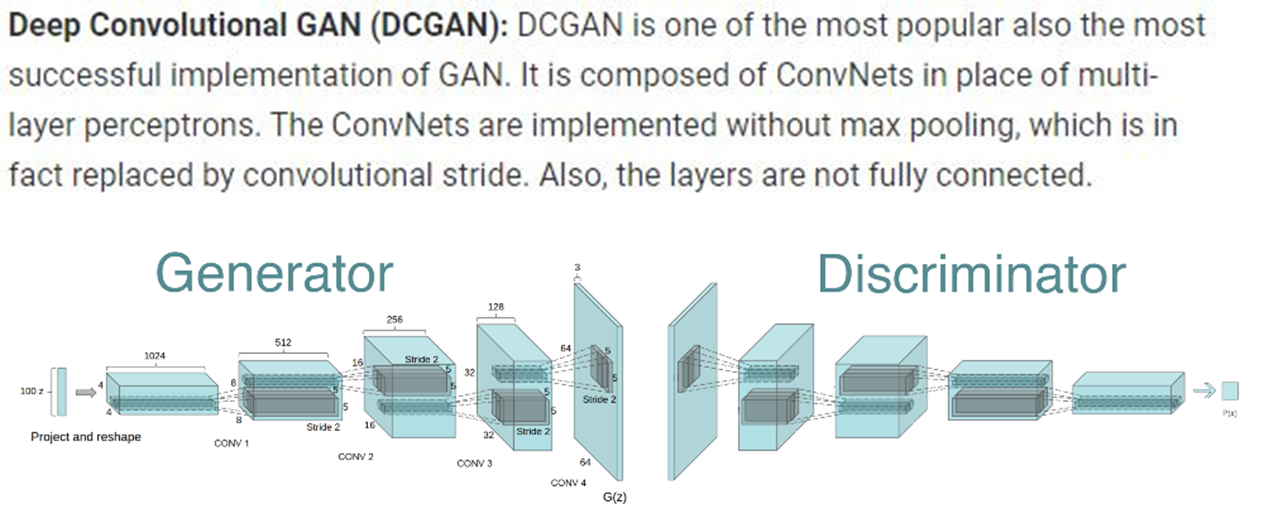
- Deep Convolutional GANs (DCGAN)
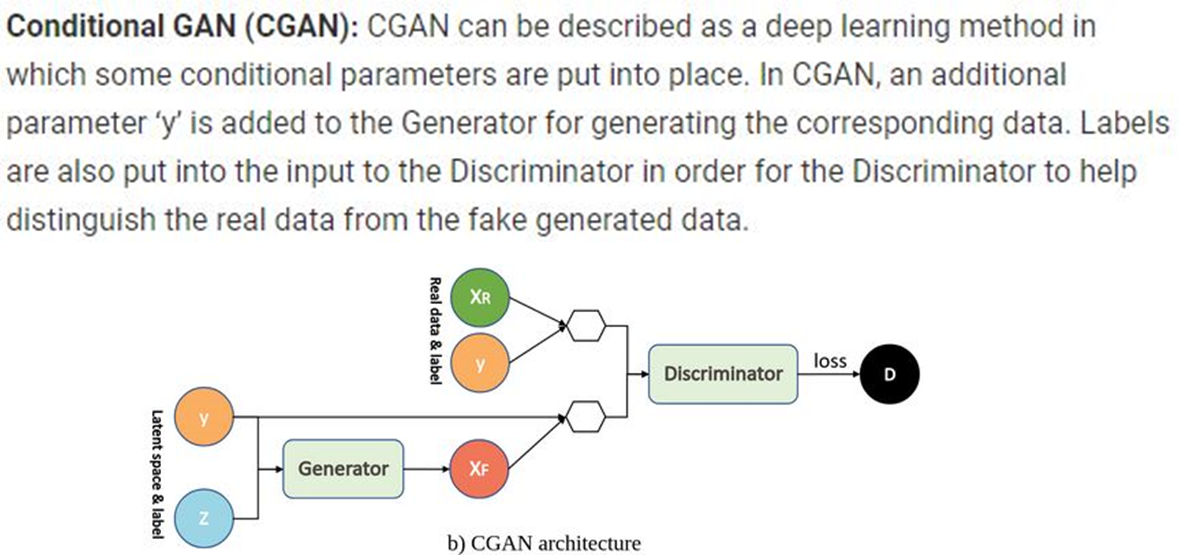
- Conditional GANs (CGAN)
- Super Resolution GAN

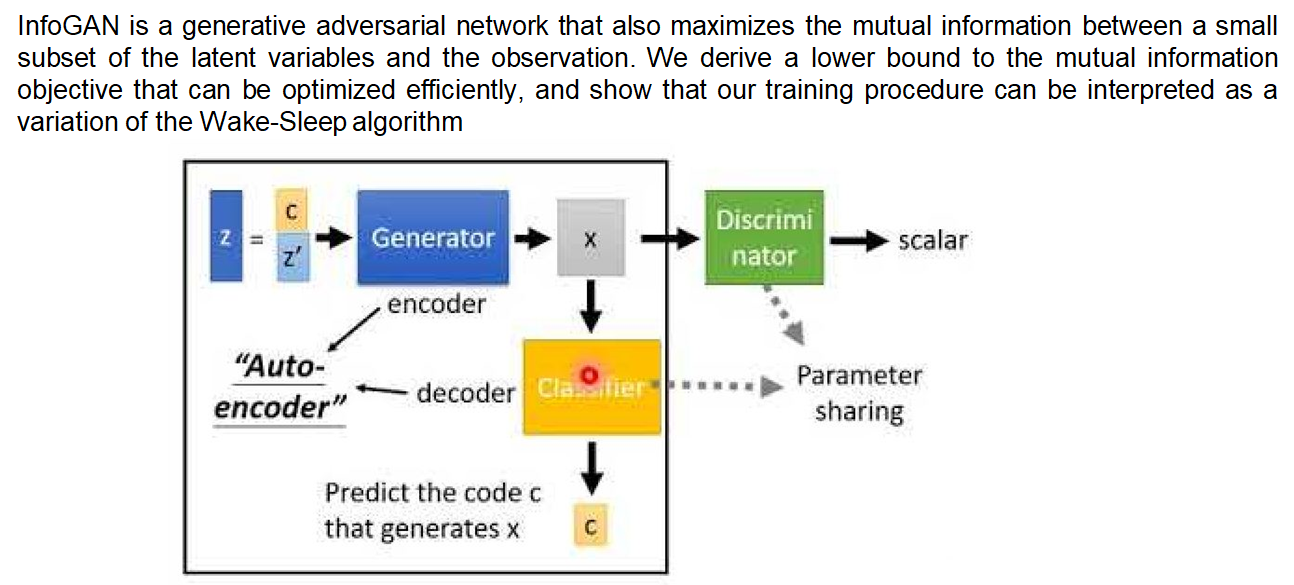
- info GAN
CONCLUSION
The main purpose of this article is to get the basic knowledge of the adversarial training evaluation of a generative model. We have discussed generative and discriminative modeling, and how they differ from each other. We discussed how GANs work and the idea behind it. We learned the training aspect of the GANs as well as the issues that arise while actually training the network.
Finally, we had a word on some well-known flavors of GANs.I think my work will help you in certain ways. If you suggest adding something more, Feel free to reach me. Just drop me a mail. See you next time with another blog!!!
References:
- Original paper: https://arxiv.org/abs/1406.2661
- https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
- https://en.wikipedia.org/wiki/Generative_adversarial_network
- https://towardsdatascience.com/a-comprehensive-guide-to-generative-adversarial-networks-gans-fcfe65d1cfe4
- https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/





