



1. Data Encoding
Label encoding and one-hot encoding are two popular data encoding methods. Let’s go over these methods in detail, with brief explanations and Python examples.
a) Label Encoding
Label encoding is a method of converting categorical variables to numerical variables. Consider the following example: a vegetable basket.

There are seven distinct vegetables in the basket: carrot, tomato, potato, onion, capsicum, radish and beans, and some of them appear more than once. Let’s try using the skleran.preprocessing.LabelEncoder function to convert these categorical data into numeric data.

We can see that the categorical variables, vegetables, are converted into numerical variables using LabelEncoder.
We can use the .classes_ operation to figure out which number represents which vegetable:
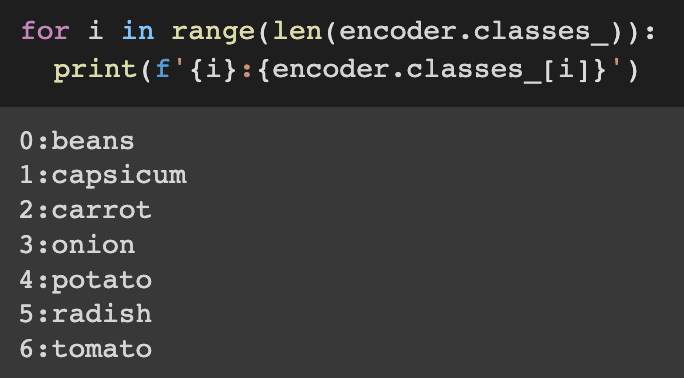
Using the function inverse_transform (), we can also convert the numerical labels back to the original categorical values.
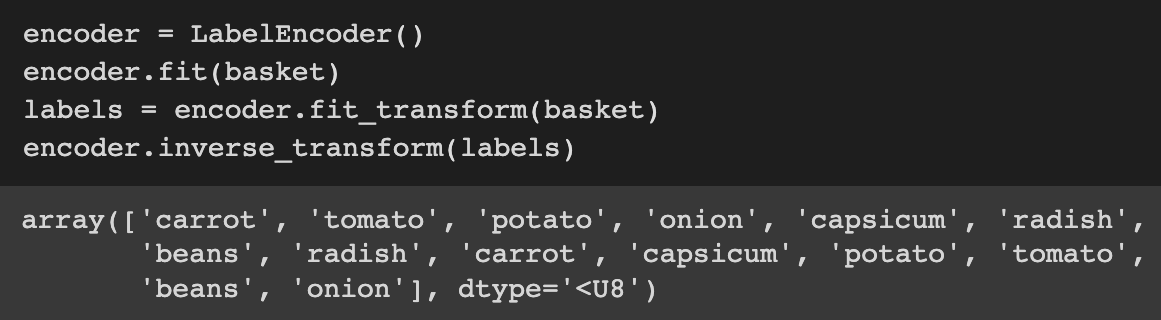
As we have seen, label encoding allows us to convert categorical values into numeric values. Label encoding, on the other hand, should be used only when absolutely necessary.
For example, using label encoding in regression models may result in critical errors because regression models will identify 2 as a greater value than 1. This means that regression models will identify carrot (2) as more important than capsicum (1), which is clearly not the case because fruits are not ordinal data in this case. As a result, we present another label encoding method known as one-hot encoding.
b) One-Hot Encoding
A little bit of visualization helps us to explain one-hot encoding.
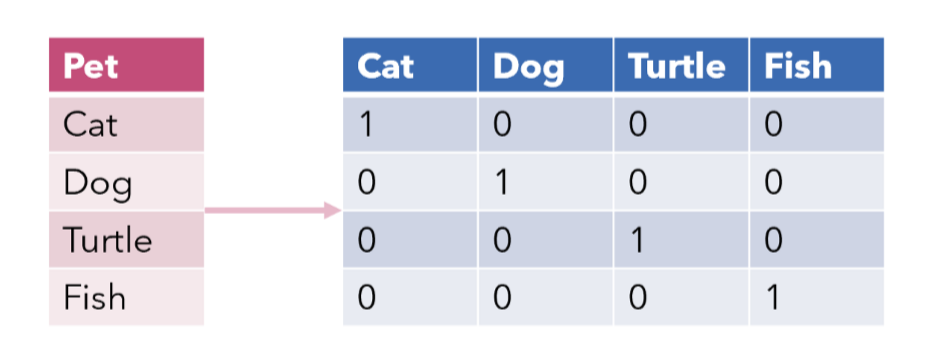
The original dataset is shown on the left in the diagram above, and the one-hot encoded dataset is shown on the right.
As can be seen, each categorical variable has new features (or columns) added, and depending on the value, a binary value (0 or 1) was assigned to the column.
For instance, in the first row, there is only “Cat,” so in the one-hot encoded dataset, “Dog”, “Turtle” and “Orange” columns received values of 0 while “Cat” received a value of 1.
Let us return to the previous example’s basket. One option is to use Scikit-Learn OneHotEncoder() to one-hot encode data, but this requires us to use LabelEncoder once more. The codes and results are shown below.
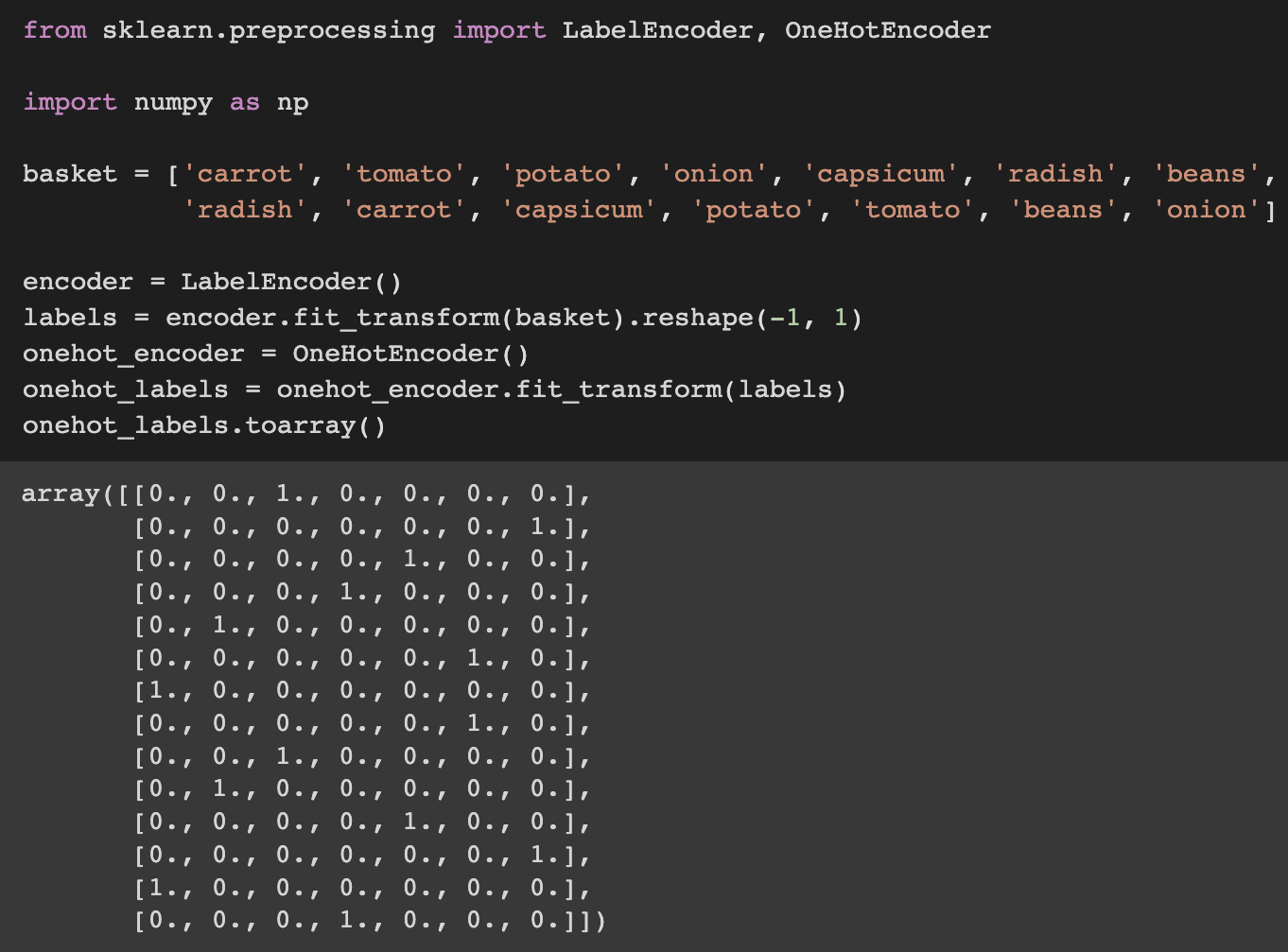
We can see that the data has been one-hot encoded using Scikit-Learn’s OneHotEncoder().
Even though Scikit-Learn is a great library for many aspects of data analytics and machine learning, there is a much easier way to do the same thing with pandas. Pandas has a function called pd.get dummies() that takes a dataframe and immediately returns a one-hot encoded dataframe.
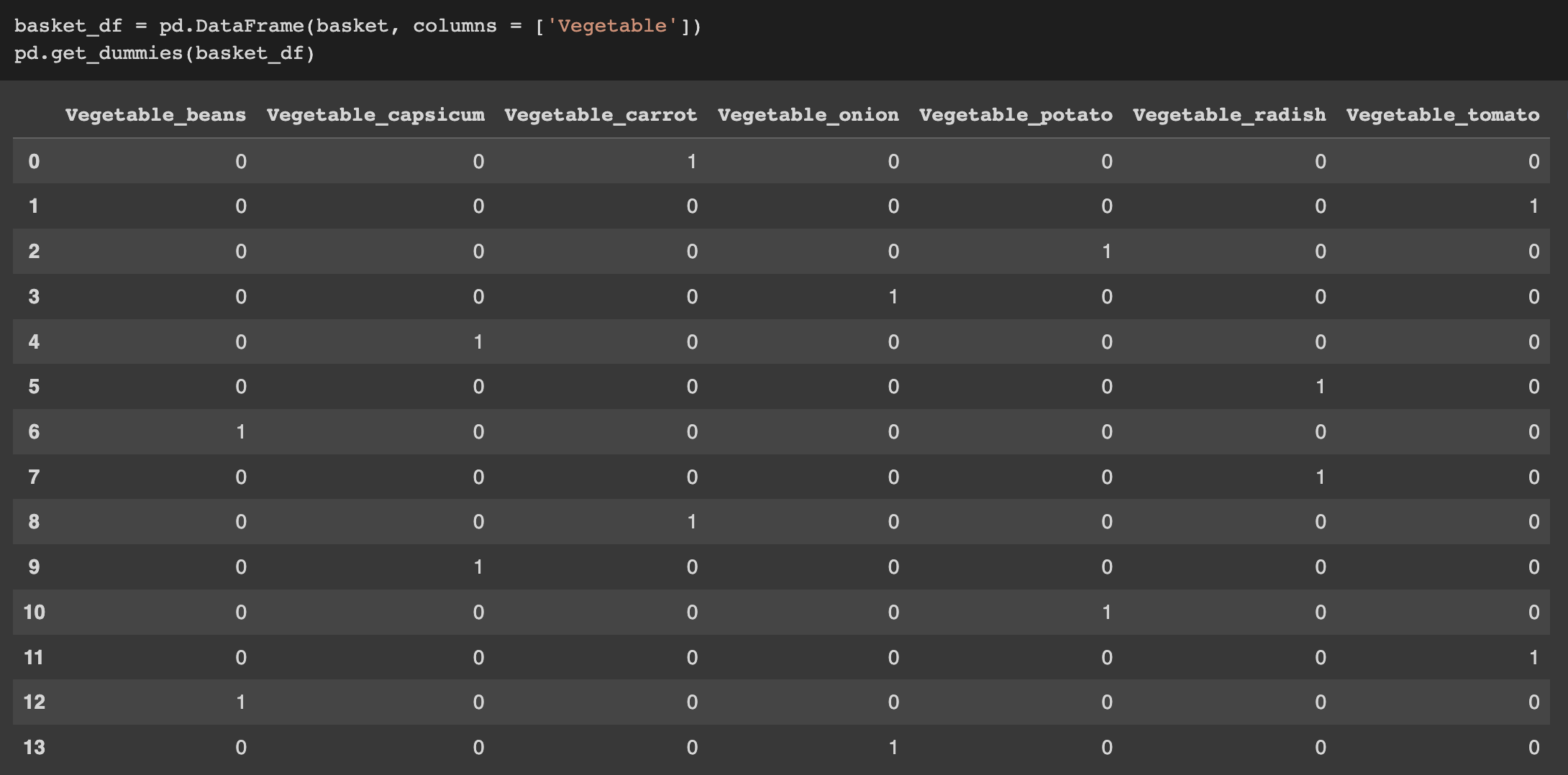
Using pd.get_dummies() instead of LabelEncoder and OneHotEncoder from Scikit-Learn could save us time and effort!
2. Feature Scaling
Feature scaling is a technique for ‘normalizing’ variables or data features. Feature scaling may be required in machine learning for a variety of reasons. It has the ability to speed up training while also smoothing the gradient descent flow.
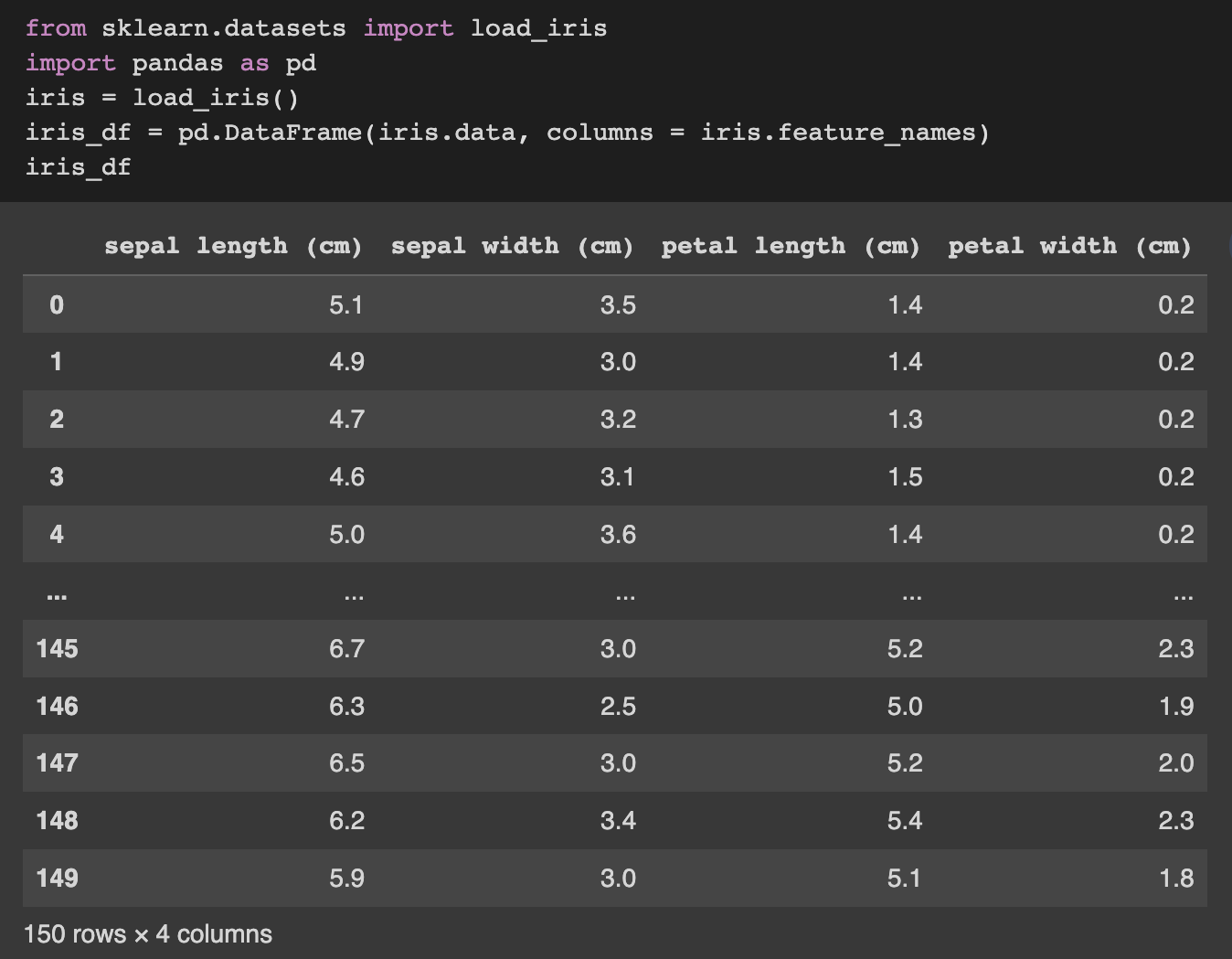
Two different feature scaling techniques from Scikit-Learn, StandardScale, and MinMaxScaler, will be examined in this section. Iris data, a dataset made available by Scikit-Learn, will be used throughout this section to understand various scalers.
a) StandardScaler()
Scikit-Learn’s StandardScaler() scales the values to have a mean of 0 and a variance of 1, or a Gaussian distribution. For some ML algorithms, it is crucial to convert the dataset so that it has a Gaussian distribution. For instance, models of logistic or linear regression rely on the assumption that data were being distributed by a Gaussian distribution.
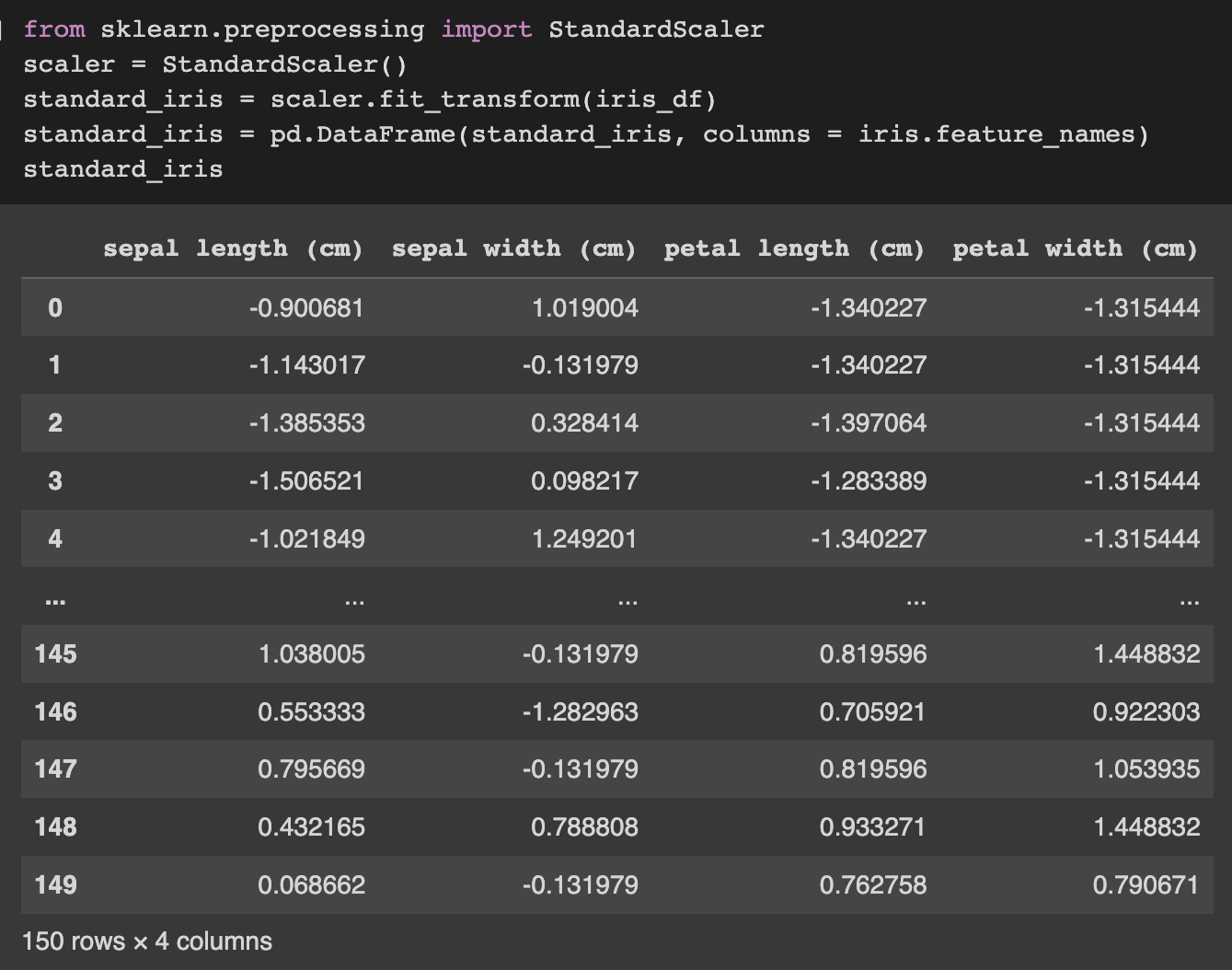
We can see that the values of the iris data have been converted in some way using StandardScaler(). Let’s verify that StandardScaler() does what it is supposed to do, which is transform the data into a Gaussian distribution.
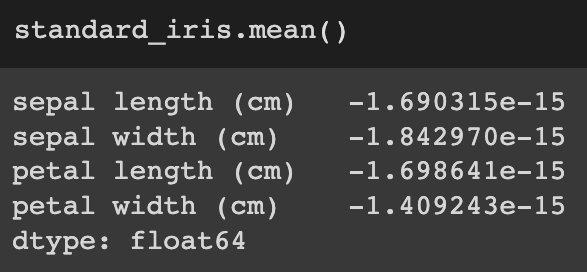

It is evident that the data has been successfully scaled because the mean is extremely close to 0 and the variance is almost 1.
b) MinMaxScaler()
MinMaxScaler() is one method of scaling data, and it converts data into some value in the range [0, 1], or else in the range [-1, 1] if there are negative values. With the iris data, since there are no negative values, the range of data should be between 0 and 1.
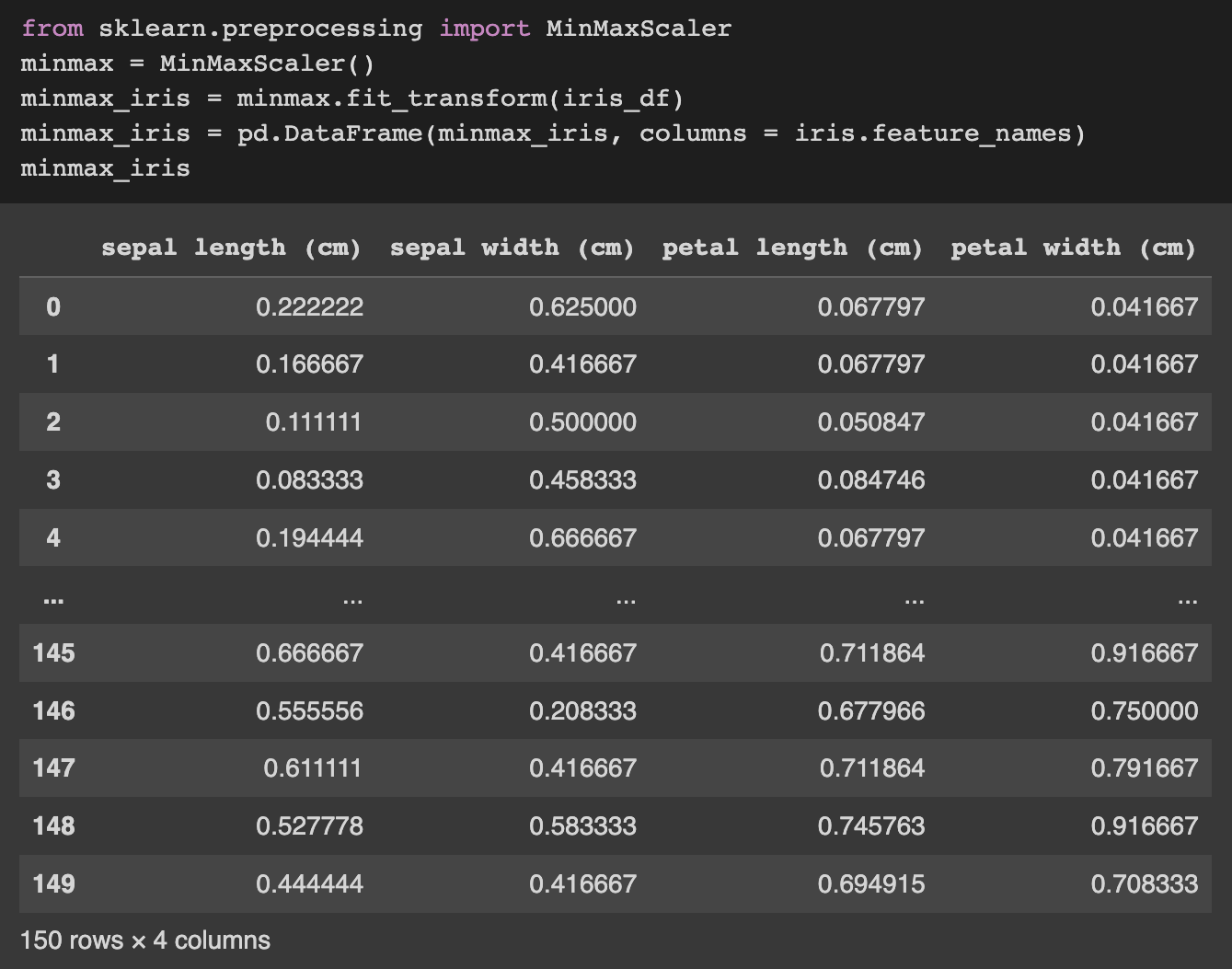
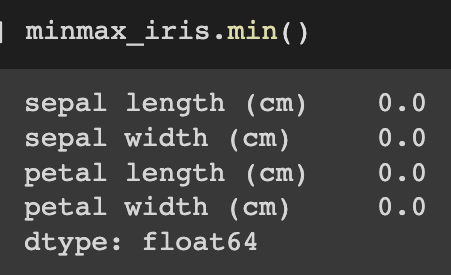

Since the minimum and maximum value for each feature are 0 and 1, respectively, we can see that the data has been minmax scaled very effectively using MinMaxScaler().
Overall, preprocessing your data is an important step in any Data Science pipeline. Scikit-learn makes it easy to preprocess our data with a wide variety of tools. In this blog, we went over some of the most commonly used preprocessing techniques, such as label encoding, one-hot encoding, and feature scaling.
If Data Preprocessing and Data Science intrigue you, start your journey with AlmaBetter’s Full Stack Data Science program. It offers 100% placement guarantee and a unique pay-after-placement model.
Read our recent blog on “5 Python Data Visualization Libraries you must try to improve your insights”.





