



Have you ever questioned how organizations like Amazon and Netflix are expecting what merchandise or films you are probably fascinated by? Or how do medical doctors decide the effectiveness of a selected medication? Linear regression analysis with Python is regularly the important thing to unlocking those insights.

We will dive deep into the fundamentals of linear regression and discover a few exciting questions that may be responded to with the use of this approach. For example, what's the connection between a person's profits and their degree of education? Can we expect a person's blood strain to be primarily based totally on age and weight? How does the rate of a product relate to its functions and purchaser reviews? We'll dive into the diverse steps worried in engaging in regression analysis.
What is Linear Regression in Python?
Linear regression is a statistical approach that lets in us to version the connection among a based variable and one or greater impartial variables. This approach is broadly used in lots of fields, together with marketing, medicine, finance, and engineering. Here are a few examples of ways linear regression can assist in one-of-a-kind industries:
Marketing: Companies like Amazon and Netflix use linear regression to are anticipating what products or movies a client might be involved in. They take a look at facts, including purchase history, and are seeking for queries and rankings to create a model which could are anticipating the client's preferences. For example, if a patron has formerly bought books on gardening and cooking, Amazon may recommend a brand new cookbook or a hard and fast of gardening tools. Linear regression permits corporations to make personalized pointers to customers that may enhance patron delight and boom sales.
Medicine: Linear regression is frequently utilized in medical trials to decide the effectiveness of a selected medicinal drug. Researchers use linear regression to version the connection among the dosage of a drug and the patient's response, inclusive of a discount in signs and symptoms or a development in excellent of life. By studying the records from medical trials, researchers can decide the choicest dosage of a drug and become aware of any capacity aspect effects. These facts can assist docs make knowledgeable selections approximately prescribing medicinal drugs to their patients.
Types of Linear Regression
- Simple Linear Regression
- Multiple Linear Regression
- Simple linear regression is a statistical technique used to analyze the relationship between variables, wherein one variable is used to predict the other. It entails fitting a straight line to a set of data points, wherein the line represents the best fitto the data. This technique is regularly utilized in finance, economics, and other fields to predict future trends or outcomes.
- Multiple linear regression, on the other hand, is a statistical technique used to analyze the relationship between 3 or more variables, where one or more variables are used to predict the other. It entails fitting a plane or hyperplane to a set of data points, wherein the plane represents the best fit to the data. This technique is regularly utilized in fields that includes marketing, engineering, and social sciences to analyze the relationship among multiple variables and predict outcomes based on those relationships.
Simple linear regression
Simple linear regression (SLR) is a method of predicting responses based on attributes. Both variables are assumed to be linearly related. Therefore, we try to find a linear equation that can most accurately predict response values (y) with respect to features or independently derived variables (x).

We describe:
x as a feature vector, i.e. x = [x1, x2, x3, ...., xn], y as the response vector, i.e. y = [y1, y2, y3 ...., yn] For n observations (n = 10 in the example above).
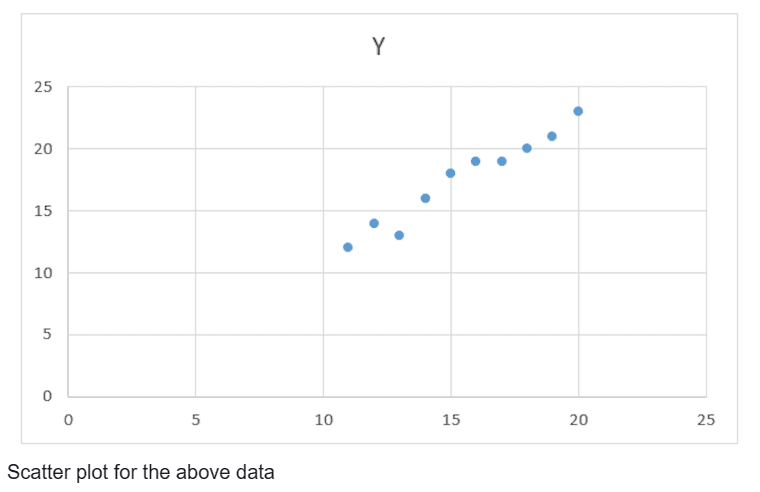
The next step is to identify the best-fit line for the scatterplot to predict the response for each new value of the characteristic.
What is a best-fit line?
In linear regression, the "best-fit line" refers to the road that pleasant represents the connection among the established and impartial variables withinside the data. It is likewise referred to as the "regression line" or the "line of best-fit". The best-fit line is decided thru a technique called "becoming the version" or "version estimation", which entails locating the values of the slope and intercept that decrease the residual sum of squares (RSS) or maximize the chance of the determined data.
The best-fit line is characterized by the equation:
Y = β0 + β1*X
where:
- Y is the dependent variable
- X is the independent variable
- β0 is the intercept, which represents the value of Y when X is 0
- β1 is the slope, which represents the change in Y for a unit change in X
- The best-fit line is decided with the aid of using estimating the values of β0 and β1 primarily based totally at the data the use of statistical methods which includes the technique of least squares.
- The slope (β1) represents the rate of extrade withinside the dependent variable (Y) for every unit extrade withinside the independent variable (X), and the intercept (β0) represents the value of the dependent variable (Y) while the independent variable (X) is zero.
- The best-fit line is positioned to decrease the gap among the observed data points and the anticipated values at the line, as represented with the aid of using the residuals.
- Once the best-fit line is estimated, it can be used to make predictions for the dependent variable (Y) primarily based totally on different independent variable values (X) within the range of the data used for model estimation.
- It offers a visible illustration of the overall trend and relationship among the variables and may be a beneficial tool for making predictions, understanding the strength and direction of the relationship, and identifying potential patterns or trends withinside the data.
- To build a model, we need to "learn" or estimate the values of the regression coefficients. Once these coefficients are determined, the model can be used to predict responses. This article uses the concept of least squares.
Consider:
Rabs(H) = (1/n) *∑(i=1to n) (y_i - H(x_i))^2
- Rabs is the residual error for the ith observation.
- Our goal is, therefore, to minimize the total residual error.
We defined the cost function or squared error J as
J(θ) = (1/(2m)) * ∑ (i=1to m) [(h(θ)(x^(i)) - y^(i))^2]
Our task is then to find the values of x(i) and y(i) that minimize J(x(i), y(i)). Without going into the mathematical details, here are the results:
β1 =SS(xy)/SS(xx)
β0 = mean(y) - β1*mean(x)
- SS(xy) is the sum of the cross deviations of "y" and "x".
SSxy = ∑(x - x̄)(y - ȳ)
- SS(xx) will be the sum of squared deviations from 'x'.
SSxx = ∑(x - x̄)²
Assumptions
The linear regression model is primarily based totally on the subsequent assumptions:
Linearity: There should be a linear relationship between the independent variables and the dependent variable.
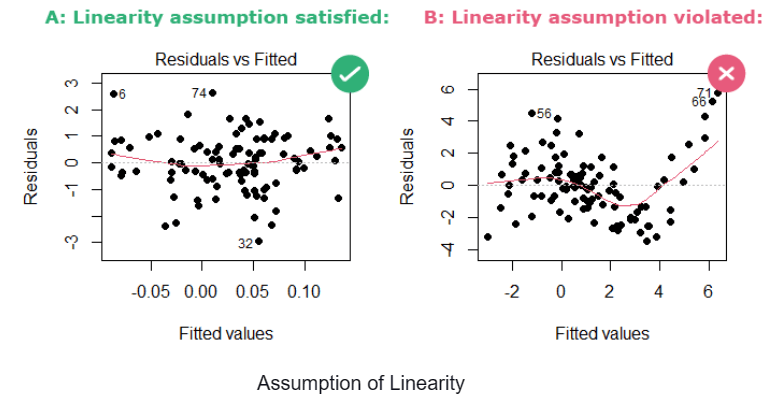
Independence: The observations should be independent of each other, that means that the value of 1 observation should not have an effect on the value of another observation.
Homoscedasticity: The variance of the errors should be constant throughout all degrees of the independent variable(s).
Normality: The errors should be normally distributed.
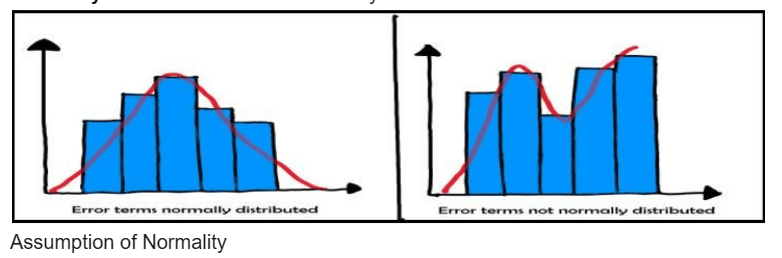
No Multicollinearity: The independent variables should not have a high correlation.
It is important to note that not following these assumptions might lead to biased or inaccurate results, so checking these assumptions before using the linear regression model is necessary.
Steps to Implement Linear Regression Python from Scratch
Simple linear regression is an extensively used statistical method used to understand the relationship among variables, wherein one variable (the dependent variable) is predicted primarily based totally on the values of another variable (the independent variable) the use of a linear equation. Here are the steps for simple linear regression with equations:
- Step 1: Define the problem Clearly define the hassle and identify the variables of interest. Decide which variable could be the dependent variable (commonly denoted as Y) and in order to be the independent variable (commonly denoted as X).
- Step 2: Collect and prepare data Collect data at the variables of interest. Ensure that the data is complete, accurate, and representative of the population of interest. Prepare the data for analysis by checking for lacking values, outliers, and different data quality issues.
- Step 3: Plot the data Create a scatter plot to visualize the relationship among the dependent and independent variables. This will assist you to decide if there may be a linear trend withinside the data.
- Step 4: Estimate the parameters Estimate the parameters of the linear regression model, which are the slope (denoted as β1) and the intercept (denoted as β0). These parameters constitute the relationship between the dependent and independent variables.
- Step 5: Fit the model Use statistical methods, which include the approach of least squares, to fit the model to the data. The purpose is to find out the values of β0 and β1 that minimize the residual sum of squares (RSS), that is the sum of the squared variations of many of the observed and predicted values of the dependent variable.
- Step 6: Assess the model Assess the goodness of fit of the model by analyzing the residuals or errors (the differences between the observed and predicted values of the dependent variable). Common methods for assessing the model include calculating the coefficient of determination (R-squared), performing hypothesis tests on the parameters, and examining diagnostic plots.
- Step 7: Make predictions Once you've got a well-fitted model, you can use it to make predictions. Simply plug in values of the independent variable into the linear regression equation to achieve predicted values for the dependent variable.
Implementing Linear Regression in Python
Let’s use the Diabetes dataset for the demo, available in sci-kit Learn. The diabetes dataset consists of 10 physiological variables (age, sex, body mass index, average blood pressure, and six blood serum measurements) measured on 442 patients with diabetes, along with a quantitative measure of disease progression after one year of treatment. The dataset is often used for regression tasks to predict the progression of the disease based on physiological variables.
Explanation:
- This code demonstrates how to perform linear regression on the diabetes dataset using sci-kit-learn in Python.
- First, the necessary libraries are imported: matplotlib for visualization, numpy for numerical computations, datasets and linear_model from sci-kit-learn, and metrics to calculate the variance score.
- Next, the diabetes dataset is loaded and assigned to the variables X and y, representing the feature matrix and target variable, respectively.
- The data is then break up into training and testing sets using the train_test_split function from sci-kit-learn. The test length is about to 0.4, that means 40% of the data is used for testing, and the random_state is set to 1 to ensure reproducibility.
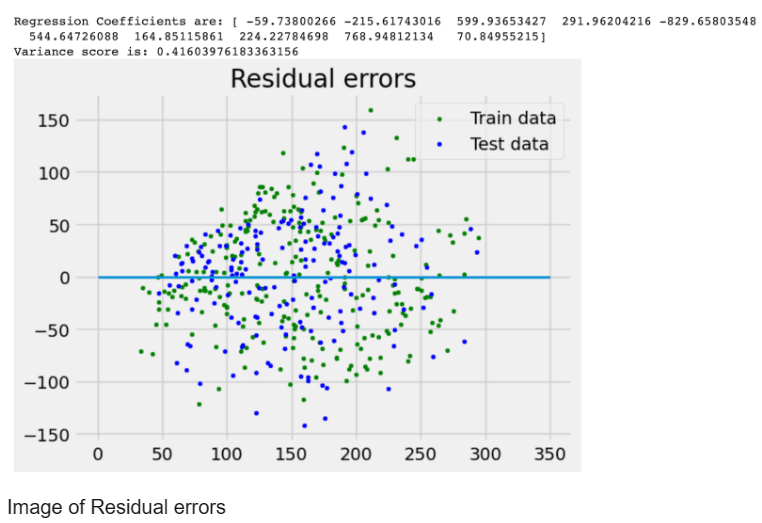
- A linear regression object is created and trained using the training sets. The regression coefficients are printed, representing the weights assigned to each feature in the model. The variance score is also printed, which indicates how well the model fits the data. A score of 1 means perfect prediction.
- Next, a residual error plot is generated to visualize the errors made by the model. The residual error is the difference between the predicted and actual values. The plot shows the residual errors in both the training and testing datasets. The line for zero residual error is also plotted.
- Finally, the plot is displayed using the plt.show() function.
Metrics Used for Linear Regression
There are numerous common metrics used for comparing the overall performance of a linear regression model. These metrics assist in evaluating how nicely the model fits the data and the way accurately it predicts the dependent variable. Here are a few commonly used metrics for linear regression:
- Mean Squared Error (MSE): MSE is defined as the average squared difference between the predicted values and the actual values of the dependent variable. It gives an indication of how closely the predicted values match the observed values, with lower values indicating better model performance. The MSE is calculated as follows:
MSE = (1/n) * ∑(Yi - Ŷi)^2
where:
- n = number of data points
- Yi = actual value of the dependent variable for the i-th observation
- Ŷi = predicted value of the dependent variable for the i-th observation
- Root Mean Squared Error (RMSE): RMSE is defined as the square root of MSE, which represents the average absolute difference between the predicted values and the actual values of the dependent variable. Like MSE, lower values of RMSE indicate better model performance. RMSE is calculated as:
RMSE = √(MSE)
- R-squared (R2) coefficient: R2 is a measure of the proportion of the entire variation withinside the dependent variable this is explained via way of means of the linear regression model. It ranges from 0 to 1, with higher values indicating a better fit. R2 is calculated as:
R2 = 1 - (SSR/SST)
where:
- SSR = sum of squared residuals (residual sum of squares)
- SST = total sum of squares
- Adjusted R-squared: Adjusted R-squared is a changed model of R2 that considers the wide variety of predictors (independent variables) withinside the model. It penalizes the inclusion of unnecessary predictors, making it an extra conservative measure of model fit. Adjusted R-squared is calculated as
Adjusted R2 = 1 - (SSR/SST) * (n-1)/(n-p-1)
where:
- n = number of data points
- p = number of predictors (independent variables)
- Residual plots: Residual plots are graphical representations of the residuals (the differences between the predicted and actual values of the dependent variable) against the independent variable or other relevant variables. Residual plots can assist in identifying patterns or trends withinside the residuals that can suggest model inadequacy or violations of assumptions.
These are a number of the commonly used metrics for evaluating the overall performance of a linear regression model. It's important to apply multiple metrics and consider the particular context of the data being analyzed to assess the model's overall performance properly.
Applications
Regression analysis is an extensively used statistical technique that enables to the identification of the relationships between a dependent variable and one or more independent variables. Here are a few common applications of regression analysis:
Forecasting: Regression models can be used to forecast future trends, such as income or stock prices, primarily based totally on historical data.
Market Research: Regression models can be utilized in market research to recognize the relationships among consumer behavior, together with purchasing habits, and factors, together with price, marketing, and demographics.
Finance: Regression models can be used to recognize the relationships among financial variables, together with interest rates and stock prices.
Economics: Regression models are widely utilized in economics to study relationships among variables, together with income and expenditure.
Quality Control: Regression models can be utilized in quality control to recognize the relationships among production variables and product quality.
Healthcare: Regression models can be used to study the relationships among medical variables, together with disease incidence and treatment outcomes.
Social Sciences: Regression models are extensively utilized in social sciences to study relationships among variables, together with education and income.
Overall, regression analysis is a versatile and powerful statistical tool that can be applied to an extensive range of fields to understand and predict relationships among variables.
Conclusion
Linear regression is a statistical technique used in various fields for modeling relationships between variables. It has applications in marketing, medicine, finance, and engineering. It involves finding the best-fit line through the model estimation, but assumptions such as linearity, independence, homoscedasticity, normality, and no multicollinearity must be met for accurate results. Python can be used for implementing linear regression by defining the problem, collecting and preparing data, plotting the data, and estimating model parameters.
Quiz
- What is linear regression?
- A statistical technique that models the relationship or helps to understand the correlation between a dependent variable and one or more independent variables.
- A technique used to collect and prepare data for analysis.
- A process of estimating the parameters of a linear equation.
- A method of finding the best-fit line for a scatterplot.
Answer: a. A statistical technique that models the relationship between a dependent variable and one or more independent variables.
- What is the purpose of a best-fit line in linear regression?
- To identify potential patterns or trends in the data.
- To check for linearity in the relationship between variables.
- To estimate the parameters of the linear equation.
- To minimize the distance between observed data points and predicted values.
Answer: d. To minimize the distance between observed data points and predicted values.
- What are the assumptions of linear regression?
- Linearity, independence, homoscedasticity, normality, and no multicollinearity.
- Homoscedasticity, linearity, independence, normality, and multicollinearity.
- Normality, homoscedasticity, linearity, independence, and multicollinearity.
- Independence, normality, homoscedasticity, multicollinearity, and linearity.
Answer: a. Linearity, independence, homoscedasticity, normality, and no multicollinearity.
- What are the steps to implement linear regression in Python?
- Define the problem, collect and prepare data, plot the data, and estimate the parameters.
- Collect and prepare data, define the problem, plot the data, and estimate the parameters.
- Plot the data, define the problem, collect and prepare data, and estimate the parameters.
- Estimate the parameters, collect and prepare data, plot the data, and define the problem.
Answer: b. Collect and prepare data, define the problem, plot the data, and estimate the parameters.
Did you know that the average salary of a Data Scientist is Rs.12 Lakhs per annum? So it's never too late to explore new things in life, especially if you're interested in pursuing a career as one of the hottest jobs of the 21st century: Data Scientist. Click here to learn more: Click here to kickstart your career as a data scientist.





