



The K-nearest neighbors (KNN) algorithm in stands as one of the foundational pillars of Machine Learning. Its simplicity, interpretability, and remarkable versatility have propelled it to popularity in the field. By drawing on the principle of "birds of a feather flock together," KNN offers a straightforward yet powerful approach to classification and regression tasks.
In the real-world landscape of data analysis,k-nearest neighbor algorithm python has found its application in diverse domains, from healthcare and finance to recommendation systems and image recognition. Its ability to make predictions based on the similarity between data points makes it a valuable tool in tackling complex problems.
In this article, we will go through the inner workings of the KNN algorithm in Machine Learning in Python and demonstrate its practical implementation. Understanding KNN classifier mechanics and harnessing its capabilities in Python will equip you with a valuable skillset for a wide array of machine learning challenges.
Understanding the K-Nearest Neighbors Algorithm
K-Nearest Neighbors (KNN) is a straightforward and intuitive machine learning algorithm used for both classification and regression tasks. At its core, KNN relies on the principle that similar data points tend to be close to each other in the feature space. Let's delve into the fundamental concepts of KNN with knn code in python:
What is KNN?
KNN is a supervised learning algorithm that makes predictions based on the majority class or average value of its "K" nearest data points in the training dataset.It is a non-parametric algorithm, meaning it doesn't make any assumptions about the underlying data distribution.
How does it work?
1. Data Points and Features: KNN operates on a dataset consisting of data points, each with multiple features or attributes. These data points can be thought of as points in a multidimensional space, where each feature represents a dimension.
2. Choosing K: The first step is to choose the value of "K," which represents the number of nearest neighbors to consider when making predictions. Typically, "K" is an odd number to avoid ties when classifying data points.
3. Distance Calculation: KNN relies on distance metrics to measure the similarity or dissimilarity between data points.Common distance metrics include Euclidean distance, Manhattan distance, and cosine similarity.
Euclidean distance, the most commonly used metric, is calculated as follows for two points, p and q, with n features:
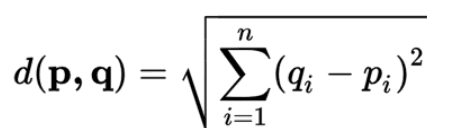
Eucledean Distance
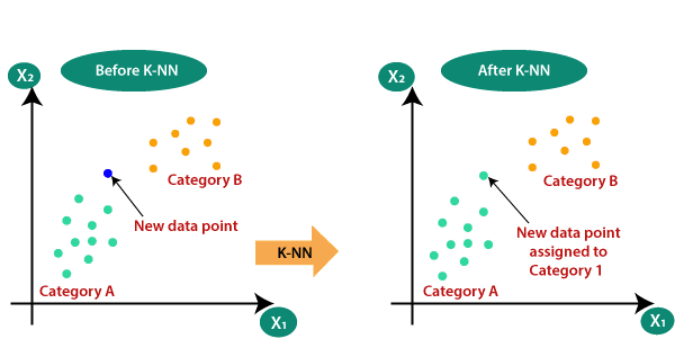
4. Finding the Neighbors: For a given data point (the one we want to make a prediction for), KNN calculates the distance between this point and all other points in the training dataset.
5. Selecting K Nearest Neighbors: KNN then selects the "K" data points with the smallest distances to the point being predicted. These "K" data points become the nearest neighbors.
- Classification (for Classification Tasks):
In classification tasks, KNN counts the class labels of the "K" nearest neighbours.
The class label that occurs most frequently among these neighbors is assigned to the new data point.
Example: If out of the "K" neighbors, 5 belong to Class A and 3 belong to Class B, the prediction for the new data point is Class A.
- Regression (for Regression Tasks):
In regression tasks, KNN calculates the average (or weighted average) of the target values of the "K" nearest neighbors. This average is assigned as the prediction for the new data point.
Example: If the target values of the "K" neighbors are [10, 12, 15, 8, 9], the prediction for the new data point is the average of these values, which is 10.8.
KNN Algorithm
The Concept of "K" (Number of Neighbors):
In KNN, "K" represents the number of nearby data points considered when making predictions.
Choosing "K" is crucial:
- Smaller "K" (e.g., 1 or 3) leads to a sensitive model, capturing fine details but susceptible to noise and outliers.
- Larger "K" (e.g., 10 or 20) results in a smoother, more stable model, but may overlook local variations.
The optimal "K" depends on the dataset and problem; it's often determined through techniques like cross-validation.
Selecting the right "K" balances sensitivity and robustness, impacting KNN's accuracy and adaptability.
Distance Metrics (e.g., Euclidean Distance) Used in KNN:
Purpose: KNN employs distance metrics to gauge the similarity or dissimilarity between data points.
Common Metrics: Some common distance metrics in KNN are:
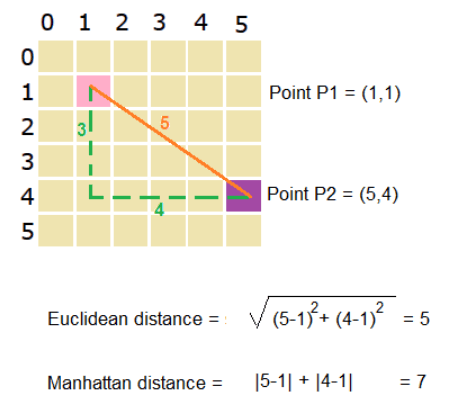
Euclidean Distance: This is the most widely used metric in KNN. It measures the straight-line distance between two points in a multidimensional space. The formula for Euclidean distance between points p and q with 2 features as follows.
Manhattan Distance: This metric calculates the distance by summing the absolute differences between the corresponding feature values. It is often used when movement can only occur along gridlines (e.g., in a city block grid).
Cosine Similarity: Rather than measuring distance, cosine similarity quantifies the cosine of the angle between two vectors. It's particularly useful when considering the orientation of data points in a high-dimensional space, such as in text analysis.
Eucledian and Manhattan Distance
These distance metrics help KNN determine the proximity of data points, aiding in neighbor selection and, subsequently, prediction. The choice of distance metric can impact the algorithm's performance, making it an essential consideration when implementing KNN.
Pros and Cons of the KNN Algorithm:
Pros of KNN Algorithm Python:
- Simplicity: KNN is easy to understand and implement, making it an excellent choice for beginners.
- Versatility: It can be used for classification and regression tasks and adapts well to various types of data.
- No training phase: KNN doesn't require a separate training phase, as it stores the entire dataset for predictions.
Cons of KNN Algorithm Python:
- Computational Complexity: As the dataset grows, the computational cost of KNN increases significantly because it involves calculating distances between data points.
- Sensitivity to Outliers: KNN can be sensitive to outliers in the data, leading to suboptimal performance.
- Curse of Dimensionality: In high-dimensional spaces, KNN may struggle to find meaningful neighbors due to the "curse of dimensionality."
Understanding these fundamental concepts and the pros and cons of KNN is crucial for effectively implementing and using the algorithm in real-world machine learning tasks.
Complete implementation of KNN Algorithm in Python
We'll use Python and the scikit-learn library for this implementation. Here is the implementation of KNN algorithm in python- a basic knn classifier python code
Step 1: Loading the Dataset
Step 2: Choosing the Value of K
Step 3: Calculating Distances
Step 4: Finding the K-Nearest Neighbors
Step 5: Making Predictions
Step 6: Evaluating the Model's Performance
Tuning and Optimizing the KNN Model
Utilizing optimization techniques in the K-Nearest Neighbors (KNN) algorithm is essential as it enhances model performance, mitigates overfitting, ensures robustness across datasets, handles complex data patterns, addresses imbalanced data, promotes generalization, improves model interpretability, and optimizes computational resources. These techniques help fine-tune KNN's hyperparameters, distance metrics, and data preprocessing steps, enabling it to adapt effectively to diverse data scenarios and deliver more accurate and reliable predictions.
Fine-tuning and optimizing the K-Nearest Neighbors (KNN) algorithm involves several key considerations and techniques to ensure it performs well in various scenarios. Here are methods to fine-tune and optimize KNN:
Cross-Validation: Use techniques like k-fold cross-validation to assess the model's performance across different values of K. Choose the K that provides the best balance between bias and variance. Common values to try are odd numbers to avoid ties.
Grid Search: Perform a grid search with a range of K values and other hyperparameters to find the best combination that optimizes model performance.
Handling Imbalanced Datasets: In real-world datasets, classes may be imbalanced, where some classes have significantly more samples than others. To address this:
Resampling: You can oversample the minority class or undersample the majority class to balance the dataset.
Use Weighted KNN: Some KNN implementations allow you to assign different weights to different neighbors, giving more importance to closer neighbors or those from the minority class.
Normalize or standardize the features before applying KNN. Feature scaling ensures that all features have the same influence on distance calculations. Common methods include Min-Max scaling and z-score normalization.
Outliers can significantly affect KNN's performance. Consider outlier detection and removal techniques to mitigate their impact on distance-based calculations.
High-dimensional data can lead to the curse of dimensionality and adversely affect KNN's performance. Consider dimensionality reduction techniques such as Principal Component Analysis (PCA) or feature selection to reduce the number of features while preserving essential information.
Learn more with our Online Python Tutorial and Python Compiler!
Conclusion
In this article, we've explored the K-Nearest Neighbors (KNN) algorithm, its key concepts, and its implementation in Python. We've emphasised the significance of choosing the right value of K, experimenting with distance metrics, and addressing challenges like imbalanced datasets. Visualisations, such as decision boundary plots and confusion matrices, provide valuable insights into the model's behavior. Implementing KNN in Python empowers data scientists and machine learning practitioners to tackle a wide range of classification and regression tasks. We encourage readers to experiment with KNN with python on their datasets and harness the algorithm's power for their machine-learning projects.





