



Every time you browse online for either shopping or watching content, a recommendation system is guiding you towards the potential item you might purchase or watch. They are so widely used now that many of us benefit from them without even knowing. We can’t possibly look through all the products or content on a website, this is where the recommendation system comes into play by giving us a better search experience, while also showing us many more products we might not discover otherwise.
In 2006 Netflix famously offered a prize to solve a simple problem that had been around for years all online. Commerce giants are fighting to get better at solving this same problem given observations of a user’s past behavior predict which other things that the same user will like, for example, based on a person’s viewing history will she like the matrix or star wars.

We can represent user preferences graphically as connections between people on one side and things on the other such as movies here, the strength of the connection is visually represented by the thickness of the lines so the problem is to fill out all of these missing connections we don’t yet know shown in red, but because of the messy unpredictable nature of people’s tastes, we can never perfectly predict what they will like because for one it involves a guess about the future based on something you’ve never seen and two the answer is always in flux because people’s tastes change over time. What we can do is try to estimate those values as best we can be using whatever data we have access to. So regardless of the context, we can describe the problem in the following mathematical form.

We use a matrix which is a collection of numbers organized into rows and columns where the rows are users and the columns are items. In this case movies and each cell in this matrix contains a number that describes how much each individual likes each movie for example we could use a scale from 0 to 5 where a 0 would represent I hate it 2 is neutral and 5 as I love it. At any given moment there will be some set of preference data for users and movies but it will be incomplete because users have only seen and rated a few movies each and so the problem boils down to trying to predict these missing values how should we make these predictions.
There are two general approaches to this problem the first is called :
Content filtering is to use the information we know about people in things as connective tissue for recommendations. It’s like asking a person questions about what kinds of movies she likes to figure out if she will like the matrix. It begins by labeling each person and movies with some known attributes or what we call features,
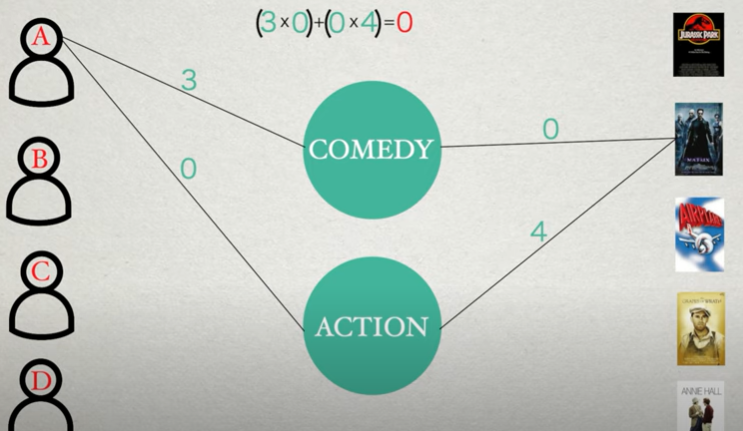
for example, action and comedy that means if a person likes comedy and hates action we can represent her as 3 0 each movie is also mapped to each feature in the same way, for example, that matrix has no comedy and lots of action so we could represent it as 0 4 and to determine whether someone will like a movie we need to multiply these factors together so we could represent the strength of the connection between the user and the matrix as 3 times 0 plus 0 times 4 equals 0 so our estimation is that she will hate the movie so to make our predictions we first need to gather this feature data for every user and movie to simplify let’s return to a matrix the representation we can store this information in two matrices. One defines the mapping between people and features the other defines the mapping between movies and futures and by multiplying these two matrices together using matrix multiplication we get an estimated strength of the connection between every person and movie and if we’d like we can normalize our data to make sure the scale stays between 0 and 4 by dividing all values by 8 and rounding to the nearest point 4 that’s one way to solve this problem is known as content filtering.

The problem is :
- it’s overly simplistic
- not very accurate
that’s because there are obviously more relevant features of a movie than just comedy or action. The obvious way to improve this is just to include more features if your call when Netflix started it did just this would ask new users to fill out a laundry list of questions about their preferences before presenting them with suggested movies and this leads to the problem of having to collect all of this preference data on users not only is it a burden for users, it’s also prone to failure as we aren’t always great at describing our own preferences. Sometimes we simply can’t explain why we like things we just do which brings us to another approach called
Collaborative filtering: The motivation for collaborative filtering comes from the idea that you will probably like things people with similar viewing habits. This idea was popularized in this 2009 paper by Cohen Bell and Wolinski. So to begin we can throw away the idea of dreaming up features used to connect people and movies. Instead, we flip things around and use the user preference data we do have to generate the features. For example, we might have this incomplete set of preference data and we will instead learn or discover the relevant features based on patterns in this data. This is done by simply reversing the problem.

We first perform an approximate factorization into two matrices and we can do this using a machine-learning approach. The job of the machine-learning algorithm is to guess values for those matrices which will match the existing data and the preference matrix as closely as possible. The simplest approach is to simply guess numbers over and over until you arrive at a set of numbers that predict the data with the lowest error overall. Once this estimation is finished we can multiply the matrices as before to fill in all of the missing values.
It’s important to note that we won’t know exactly what to label these discovered features. So we call them latent features because they arise out of the underlying patterns and the data. You can think of them as an average or weighted sum of the patterns in the data are not based on a human-defined feature such as comedy. That’s the key insight behind this method. With content filtering the features come from the human mind whereas with collaborative filtering the features are extracted directly from the patterns in the data. This will predict the data in the same way but more accurately.
It’s also important to notice that this kind of prediction is actually a form of compression because we can represent a huge matrix of preference data by two smaller matrices of feature data. Once our feature data is determined or learned we can throw away the original data we started with because we can simply multiply the features together to recreate that data. The reason this is possible is that the preference data we started with is not random but follows patterns that exist across people. If instead the preference data was filled with random numbers we would not be able to compress it accurately because there would be no patterns to extract.
This collaborative filtering approach has also been applied to a wide range of contexts such as evaluating policy outcomes before they are implemented in the real world known as synthetic control. For example, if we wanted to understand the effect of gun control or minimum wage increases in some city we could look at the effect in similar cities first which have implemented those policies to approximate the outcome using the same mechanism. So it is the patterns we share that allow this method to work. Recommendation systems based on the ideas are in widespread use today whether it’s movies music news articles or anything else you search for online the things that are recommended to you are based on patterns the machine has observed in other people who are similar to yourself.
But Collaborative Filtering comes with its own shortcomings. One such problem in such kinds of systems is the problem of Cold-Start.
Cold- Start represents in a literal sense a situation when the engine is cold and we were are unable to start it. The user or visitor cold start simply means that when a recommendation system meets a new user for the first time and thus there is a lack of history about her preferences. Getting to know your user is critical in creating a great user experience for them.
It is faced when we have
- A new user.
- A new product
- A new recommender system is in place.
Remedies for the cold start problem is :
When we have a new user :
1.Start by recommending whatever is newer, cheaper, or popular. Popular items are highly likely to be liked by the user because it is popular and it is easier to build a profile on popular items.
2.Recommend demographically relevant products. For example, if it is a movie recommendation system you can recommend Punjabi songs to a user situated in Punjab.
3.Recommend product according to age, sex, or geography.
- Use other sources of data like social network data.
**When we have a new recommender system: **
1.Design a Non-Recommender system that captures data to feed it later to the recommender system.
- Get similar data from other sources.
Six Examples of Recommender Systems
Recommender systems work behind the scenes on many of the world’s most popular websites. E-commerce websites, for example, often use recommender systems to increase user engagement and drive purchases, but suggestions are highly dependent on the quality and quantity of data that freemium (free service to use/the user is the product) companies already have in place.
1. AMAZON
When we buy something or browse anything on Amazon, we see recommended products based on our likes or search results on the page.

As we can see above, I may have searched for products related to Sudha Murthy, but Amazon clusters it into segments based on other previous search results. A recommender system often biases the user’s opinion.
2. IMDB
When we rate a TV show or movie on IMDb it recommends other shows or movies based on important details like cast, genre, sub-genre, plot, and summary.

As we can see above, I was recommended to rate Frozen Planet because I’ve watched David Attenborough’s wildlife documentary series. In this case, IMDb suggested this to me based on the cast of the series.
3. FACEBOOK & INSTAGRAM
Facebook and Instagram use recommender systems on a wider scale for suggesting friends and stories in the newsfeed.

Often in the newsfeed section, the user is bombarded with articles similar to one another based on the likes and pages they follow. Some argue it creates an unconscious bias among the user, which may be bad or useful depending on how the user interprets something when they have only one side of the argument.
4. YOUTUBE
YouTube recommends videos based on previous clicks.

As we can see above, the first video is about Google. While I’ve seen the video, YouTube recommends it to me again.
5. GOOGLE
Whenever we are logged in and search on Google, it is stored in our history and recommends products based on our previous searches. Not surprisingly, more than 95% of the company’s revenue is generated through advertising.


From the above, we can see we were getting targeted with these advertisements based on recent search results.
6. ANOTHER GOOGLE SUBSIDIARY- GMAIL

Gmail’s Sponsored Ad
Gmail recommends advertisements based on my personal inbox and tags they may have generated.
Other examples of recommender systems at work include movies on Netflix, songs on Spotify, and profiles on Bumble.
To summarise:
In this article we understood how the Recommendation System works and the difference between Collaborative Filtering vs Content-Based Filtering and their working. Both methods have their own set of advantages and disadvantages. We defined the problem of a cold start and saw some ways to tackle it. In the end, we saw some use cases of recommendation systems in big tech giants. Recommendation systems are very widely used in the tech industry, there are many kinds of research going on to develop more features in the recommender. I’ll be writing a second part for the codes(building recommender systems)and other technological advancements in this area of machine learning.
Happy learning!





