



Have you ever wondered how data scientists choose clustering techniques as a tool for solving real-world problems?
Let’s take, for example, you work as a data scientist for a telecommunications company in which your company is struggling with consumer churn, and you have been tasked with figuring out which customers are at the highest threat of leaving. The questions that arise are how data scientists use clustering strategies to solve real-world problems.

By the end of this article, you'll better understand how data scientists use clustering strategies to gain valuable insights and make informed decisions to enhance their businesses.
What is Clustering in Data Science?
Clustering or cluster examination could be a Machine Learning method that groups the unlabelled dataset. It can be characterized as "A way of grouping the data points into diverse clusters comprising comparable data points. The objects with the possible similarities stay in a group with less or no similitudes with another group."
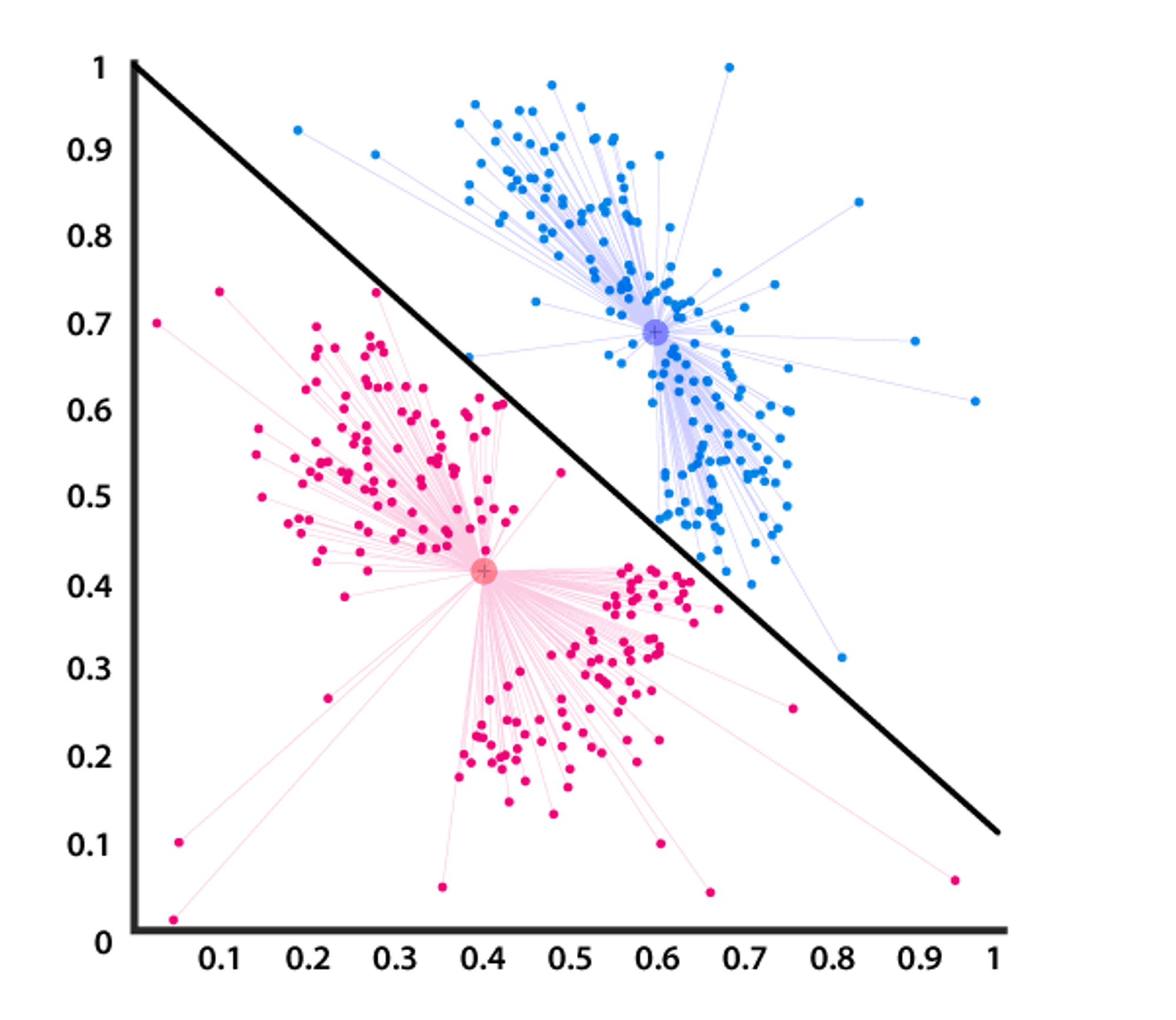
It does this by finding a few similar patterns within the unlabelled dataset, such as shape, estimate, color, behavior, etc. It separates them as per the presence and absence of those comparative designs. It is an unsupervised learning strategy, subsequently, no supervision is given to the algorithm, and it deals with the unlabeled dataset.
After applying this clustering procedure, each cluster or group is given a cluster ID. ML framework can utilize this id to rearrange the processing of expansive and complex datasets.
Clustering Strategy in the Real World
Let's understand the clustering strategy with the real-world case of a shopping center:
When we visit any shopping center, we are able to watch that the things with comparative utilization are assembled together. Such as, the t-shirts are gathered in one area, and the pants are in other segments. Essentially, in vegetable segments, apples, bananas, Mangoes, etc., are assembled in separate areas so that we can effectively discover things. The clustering procedure, moreover, works in the same way. Other illustrations of clustering are gathering records agreeing to the subject. The clustering method can be broadly utilized in different assignments. A few most common employments of this strategy are:
- Market Segmentation
- Statistical data analysis
- Social network analysis
- Image segmentation
- Anomaly detection, etc.
Apart from these common applications, it is utilized by Amazon in its recommendation framework to supply recommendations as per the past search of items. As per the watch history, Netflix also uses this procedure to suggest movies and web series to its clients.
Types of Clustering Methods
The clustering strategies are broadly partitioned into Hard clustering (data points belonging to only one gather) and Soft Clustering (data points can belong to another group also). But there are also other different approaches to Clustering exist. Underneath are the most clustering strategies utilized in Machine learning:
- Partitioning Clustering
- Density-Based Clustering
- Distribution Model-Based Clustering
- Hierarchical Clustering
- Fuzzy Clustering
Let’s learn about them in detail:
1. Partitioning clustering:
This technique divides the data points right into a given number of non-overlapping clusters. The most commonly used partitioning algorithm is K-Means. The algorithm attempts to minimize the sum of the squared distances between each data point and the assigned cluster centroid. However, K-means is limited to being sensitive to the preliminary preference of centroids, so it can need to be run multiple times with extraordinary starting points to get good clustering results.
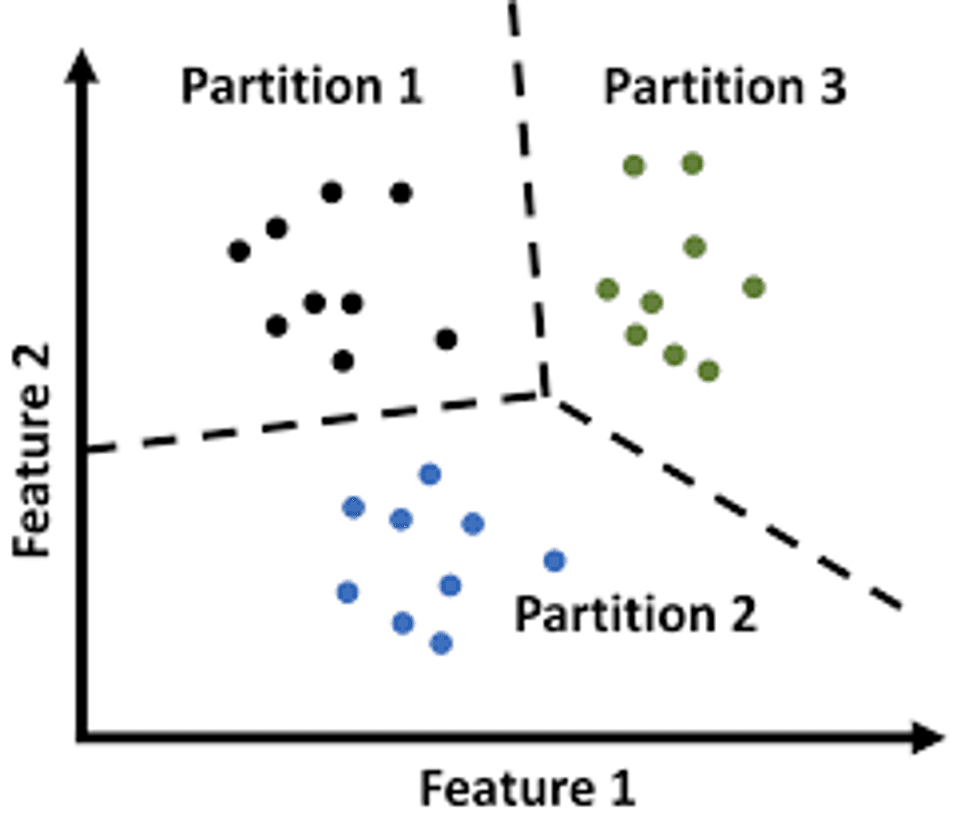
Example:
The most popular example of partitioning clustering is the k-means algorithm. In the k-means algorithm, the user specifies the number of clusters, k, that they want to partition the data into. The algorithm then randomly selects k data points to act as the initial centroids for the clusters. It then iteratively assigns each data point in the dataset to the nearest centroid and recalculates the centroids based on the mean of the data points in each cluster. This process continues until the centroids no longer move or a maximum number of iterations is reached.
2. Density-based clustering:
This approach organizations records factors primarily based totally on their proximity to excessive-density areas of records factors. This method is beneficial while the clusters are irregularly shaped and now no longer well-separated. The most commonly used density-primarily based totally clustering algorithm is DBSCAN (Density-Based Spatial Clustering of Applications with Noise), which defines a cluster as a region of high density surrounded with the aid of using a region of low density. DBSCAN can pick out noise points that don't belong to any cluster.

Example:
An example of density-based clustering is the DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm. This algorithm requires two input parameters, epsilon (ε) and the minimum number of points (MinPts) to form a cluster. The algorithm starts by selecting a random data point and identifies all other data points within the radius of epsilon. If the number of data points within the radius of epsilon is greater than or equal to MinPts, then a new cluster is formed. This process is repeated until all the data points are assigned to a cluster or considered as noise.
3. Model-based clustering:
This technique assumes that data points are generated from a mixture of probability distributions, with every cluster represented via way of means of a different distribution. Model-based clustering entails estimating the parameters of those distributions and assigning data points to clusters based on their chance of belonging to every distribution. The most commonly used model-primarily based totally clustering algorithm is the Gaussian Mixture Model (GMM), which assumes that data points are generated from a mixture of Gaussian distributions. GMM can handle clusters of different shapes and sizes.
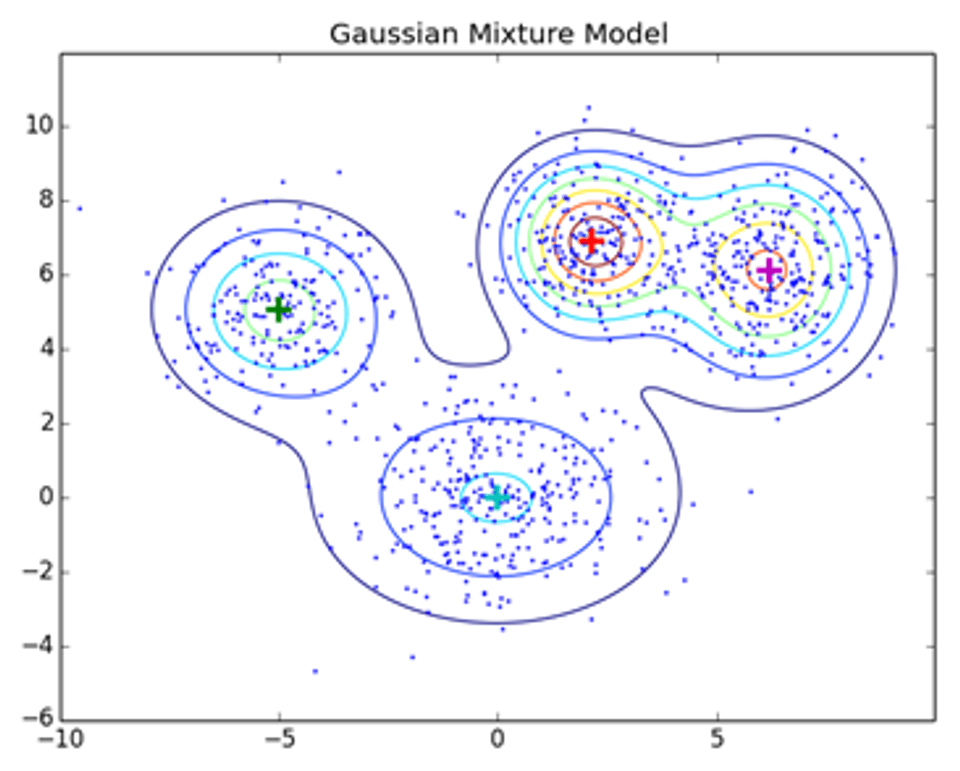
Example:
The most commonly used model-based clustering algorithm is the Gaussian Mixture Model (GMM), which assumes that the data points are generated from a mixture of several Gaussian distributions. The algorithm estimates the parameters of the Gaussian distributions and assigns each data point to one of the distributions or clusters based on the probability of the point belonging to that cluster. This approach is useful for identifying clusters in data where the underlying distribution is not well-defined or where the data is high-dimensional.
4. Hierarchical clustering:
This approach entails developing a hierarchy of clusters via way of means of recursively merging or dividing clusters primarily based totally at the similarity among their data points. Hierarchical clustering can be either agglomerative or divisive. Agglomerative clustering starts with every data point as its own cluster and iteratively merges the nearest pairs of clusters till a single cluster containing all data points is formed. Divisive clustering starts with all data points in a single cluster and iteratively divides the cluster till every data point is in its own cluster.
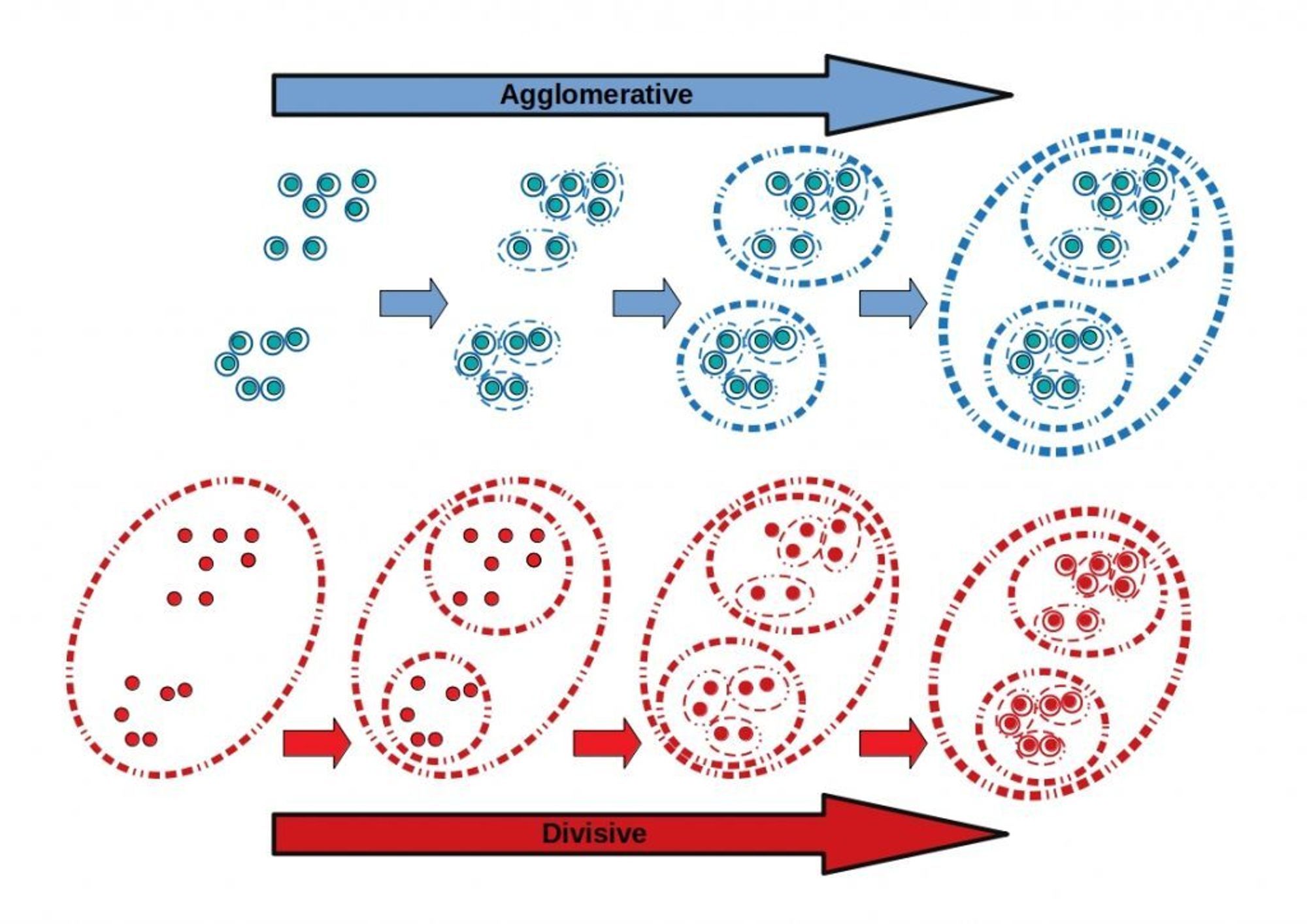
Example:
An example of hierarchical clustering can be clustering a set of animals based on their physical characteristics. The algorithm will start by considering each animal as a separate cluster and then combine them iteratively based on their similarities, such as size, shape, color, etc. The resulting dendrogram will show the hierarchical relationships between the animals, such as which animals are more closely related to each other based on their physical characteristics.
5. Fuzzy clustering:
This approach lets in data points to belong to multiple cluster, with every cluster having a degree of membership for every data point. Fuzzy clustering is beneficial while the boundaries among clusters aren't well-defined. The most commonly used fuzzy clustering algorithm is Fuzzy C-means (FCM), which assigns membership degrees to data points based on their proximity to the centroids of every cluster.
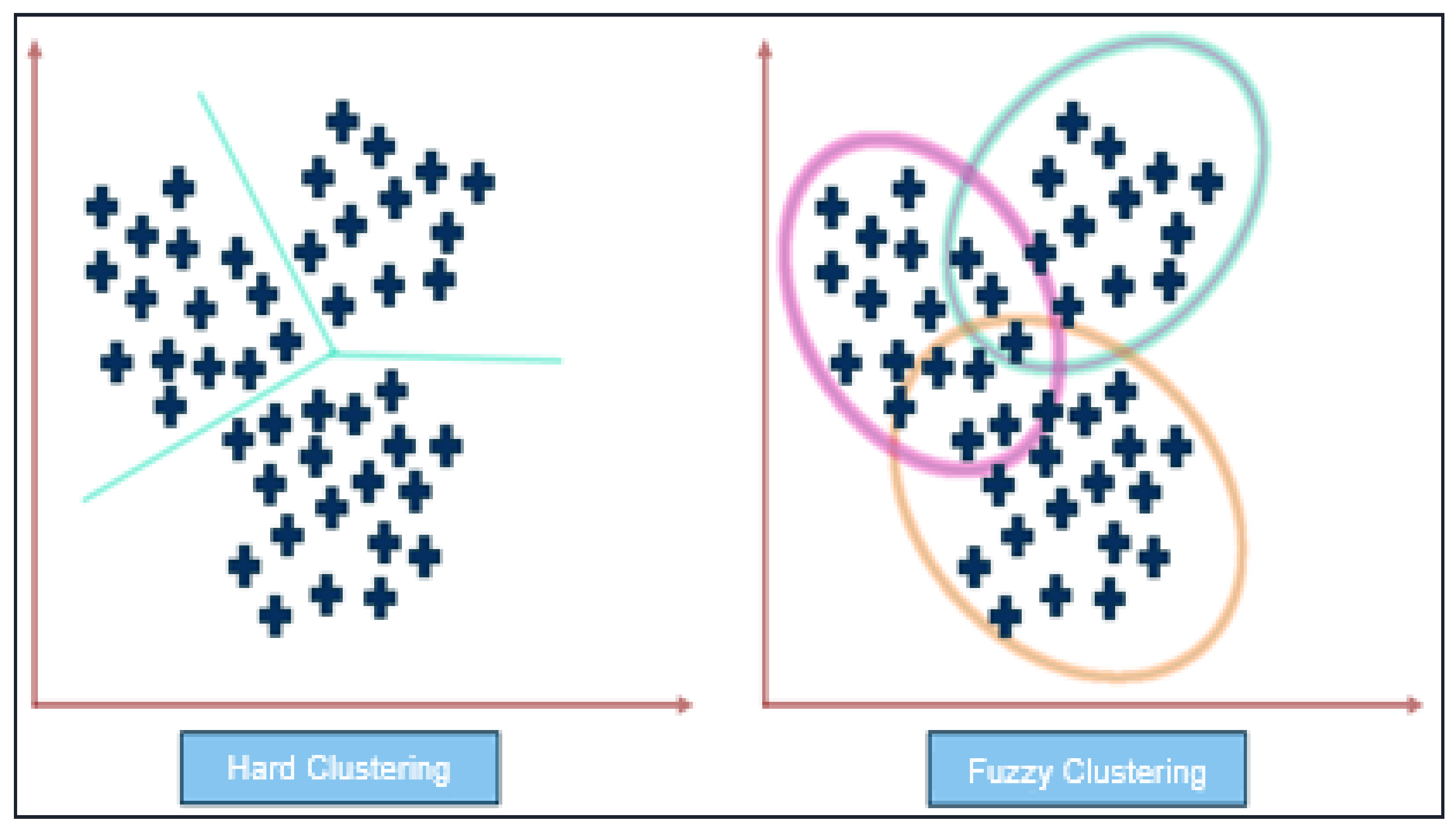
Example:
An example of fuzzy clustering can be in customer segmentation, where a company wants to group customers into different categories based on their purchasing behavior. Fuzzy clustering can help in identifying overlapping segments, where a customer can belong to multiple segments with varying degrees of membership. This can provide more nuanced insights for targeted marketing and product recommendations.
Choice of Algorithms
Each form of clustering algorithm has its very own strengths and weaknesses, and the selection of algorithm relies upon at the particular problem and the characteristics of the data.
1. K-Means algorithm:
The K-Means algorithm is a popular clustering algorithm for classifying data into clusters with equal variances. The number of clusters is specified beforehand, and the algorithm assigns each data point to the closest centroid. The centroids are then updated based on the mean of the assigned points, and this process is repeated until convergence. K-Means is fast and efficient, making it suitable for large datasets.
2. Mean-shift algorithm:
The Mean-shift algorithm is another centroid-based model that works by finding dense areas in the smooth density of data points. The algorithm works by updating the candidate for the centroid to be the middle of the points within a given region. The algorithm does now no longer require the number of clusters to be specified beforehand, making it appropriate for datasets with an unknown number of clusters.
3. DBSCAN Algorithm:
The DBSCAN algorithm is a density-based model that separates areas of high density from those of low density. The algorithm works by identifying core points and expanding the clusters around them. The advantage of this algorithm is that it can identify clusters in any arbitrary shape, making it suitable for complex datasets.
4. Expectation-Maximization Clustering using GMM:
The Expectation-Maximization algorithm is an alternative to the K-Means algorithm and is utilized in cases where the K-Means might also additionally fail. The algorithm assumes that the data points are Gaussian distributed and works with the aid of using estimating the parameters of a Gaussian mixture model. The algorithm is powerful in figuring out clusters with different shapes and sizes.
5. Agglomerative Hierarchical algorithm:
The Agglomerative hierarchical algorithm is a bottom-up hierarchical clustering algorithm. The algorithm starts by treating each data point as a single cluster and then successively merges the clusters based on the distance between them. The algorithm creates a tree structure that can be used to represent the cluster hierarchy.
6. Affinity Propagation:
The Affinity Propagation algorithm is a completely unique clustering algorithm that doesn't require the number of clusters to be precise beforehand. The algorithm works with the aid of using treating every data point as a capability exemplar and allowing the data points to send messages to every otherThe algorithm converges when the messages stabilize, and the exemplars are assigned to clusters. The algorithm has a time complexity of O(N2T), which can be a drawback for large datasets.
Applications of Clustering:

Clustering has many real-world applications across various fields, including:
- Marketing: Clustering can be used to segment customers based on their purchase patterns and behavior, allowing marketers to tailor their messaging and promotions to specific customer segments.
- Image and Object Recognition: Clustering algorithms can be used to identify similar patterns and groups within image datasets, allowing for image recognition and object classification.
- Healthcare: Clustering can be used to identify patient subgroups based on their medical history, symptoms, and treatment outcomes, which can help improve treatment plans and outcomes.
- Recommendation Systems: Clustering can be used in recommendation systems to group users based on their preferences and interests and recommend items to them accordingly.
- Social Network Analysis: Clustering can be used to identify communities and groups within social networks based on shared interests, connections, and interactions.
- Anomaly Detection: Clustering can be used to identify anomalies in datasets, such as fraudulent transactions or abnormal behaviour patterns.
- Natural Language Processing: Clustering may be utilized in text analysis to group similar documents or identify topics within a huge corpus of text.
Overall, clustering is a effective tool for identifying patterns and relationships inside complex datasets, making it beneficial throughout a huge range of industries and applications.
Implementation of Clustering Using KMeans
Let’s use the sklearn iris dataset for the demonstration of the KMeans algorithm
Code
Explanation:
The given code demonstrates the use of the K-Means clustering algorithm from the Scikit-learn library to cluster the Iris dataset and visualize the clusters the use of Matplotlib. Here is a step by step explanation of the code:
- Import required libraries: The first 3 lines import the necessary libraries - load_iris from sklearn.datasets to load the Iris dataset, KMeans from sklearn.cluster to apply K-Means clustering, and pyplot from matplotlib to visualise the clusters. 2. Load the Iris dataset: The fourth line loads the Iris dataset right into a variable known as iris.
- Prepare data: The fifth line extracts the feature data from the Iris dataset and assigns it to a variable called X.
- Apply K-Means clustering: The next four lines create an instance of KMeans with n_clusters=3, fit the data X to the model, and obtain the cluster labels and centers using kmeans.labels_ and kmeans.cluster_centers_ respectively.
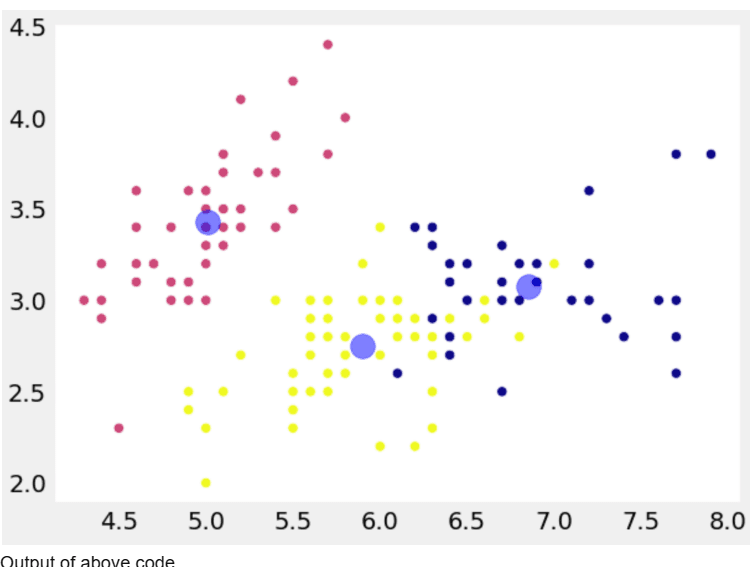
- Visualize the clusters: The last three lines plot the data points in the first two features of X using plt.scatter and assign the cluster labels as the color of each point. Additionally, the cluster centers are plotted as red circles using plt.scatter with the coordinates of the centers and a larger size (s=200) and reduced opacity (alpha=0.5) for better visualization. Finally, the plot is displayed using plt.show().
The above code makes use of K-Means clustering to cluster the Iris dataset into 3 distinct clusters and visualize them in a scatter plot, wherein every point represents a data point from the dataset, and the color and shape of the point indicate its cluster membership.
Output:
Conclusion
In conclusion, clustering is a powerful unsupervised machine learning technique used to organization unlabelled data factors into similar clusters. Data scientists use clustering algorithms to gain valuable insights and make informed decisions to solve real-world problems. Each technique has its personal advantages and disadvantages, and data scientists need to cautiously consider the specific problem and data characteristics to choose the best clustering method.
Interview Questions
What is clustering?
Answer: Clustering is unsupervised learning because it does not have a target variable or class label. Clustering divides s given data observations into several groups (clusters) or a bunch of observations based on certain similarities. For example, segmenting customers, grouping super-market products such as cheese, meat products, appliances, etc.
How the K-means algorithm work?
Answer: Kmeans algorithm is an iterative algorithm that partitions the dataset into a pre-defined number of groups or clusters where each observation belongs to only one group.
K-means algorithm works in the following steps:
- Randomly initialize the k initial centers.
- Assigned observation to the nearest center and form the groups.
- Find the mean point of each cluster. Update the center coordinates and reassign the observations to the new cluster centers.
- Repeat steps 2–3 until there is no change in the cluster observations.
How to choose the number of clusters or K in the k-means algorithm?
Answer: Elbow Criteria: This method is used to choose the optimal number of clusters (groups) of objects. It says that we should choose a number of clusters so that adding another cluster needs to add more information to continue the process. The percentage of variance explained is the ratio of the between-group variance to the total variance. It selects the point where marginal gain will drop.
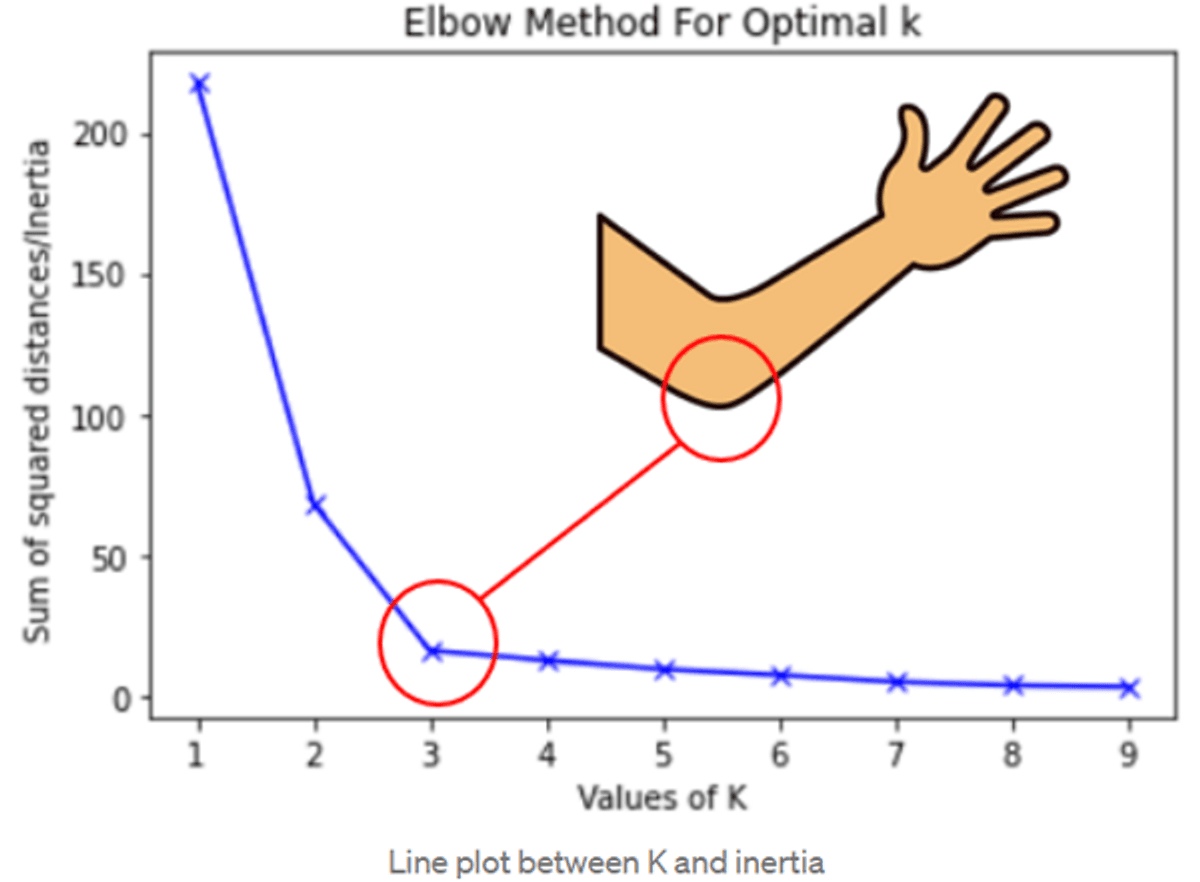
You can also create an elbow method graph between the within-cluster sum of squares(WCSS) and the number of clusters K. Here, the within-cluster sum of squares(WCSS) is a cost function that decreases with an increase in the number of clusters. The Elbow plot looks like an arm, then the elbow on the arm is an optimal number of k.
What are some disadvantages of K-means?
Answer: There are the following disadvantages:
- The k-means method is not guaranteed to converge to the global optimum and often terminates at a local optimum.
- The final results depend upon the initial random selection of cluster centers.
- Needs the number of clusters in advance to input the algorithm.
- Not suitable for convex shape clusters.
- It is sensitive to noise and outlier data points.
Did you know that the average salary of a Data Scientist is Rs.12 Lakhs per annum? So it's never too late to explore new things in life, especially if you're interested in pursuing a career as one of the hottest jobs of the 21st century: Data Scientist. Click here to learn more: Click here to kickstart your career as a data scientist.





