Your Success, Our Mission!
6000+ Careers Transformed.
Content-Based Filtering is one of the earliest and most intuitive approaches to building recommendation systems. It works on the principle that if a user liked something in the past, they are likely to enjoy similar things in the future. This similarity is determined using the intrinsic properties of the items themselves.
For example, the genre, keywords, actors, or textual descriptions of a movie. The system builds a user profile based on the features of items the user has previously interacted with. This profile then serves as a reference point to identify new items with comparable characteristics.
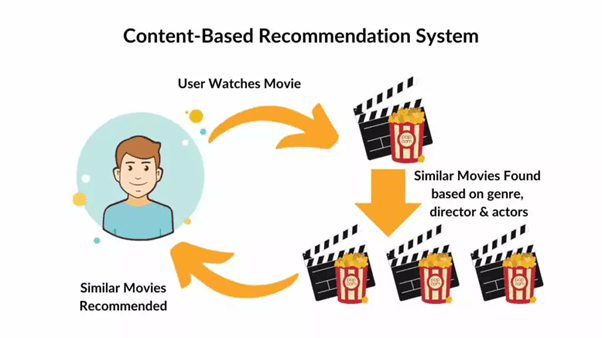
In practice, this means if a user frequently listens to soft rock songs by Coldplay and John Mayer, the system learns that the user prefers mellow acoustic tracks and recommends similar artists or songs. Similarly, if someone reads tech articles about artificial intelligence and data science, a content-based news recommender will suggest more articles containing related terms. Such systems are widely used in streaming platforms like Spotify and Netflix, e-commerce platforms like Amazon, and news aggregators such as Google News. The personalization feels highly tailored because every recommendation stems directly from the user’s own history.
However, content-based filtering is not without limitations. It often struggles with over-specialization, meaning it repeatedly recommends items that are too similar to what the user has already consumed, leading to a lack of discovery or diversity. Moreover, the system requires detailed and structured item metadata, which might not always be available or easy to extract — for instance, understanding the “theme” of a movie from its raw text description. Despite these challenges, content-based filtering remains a powerful and interpretable foundation in recommendation systems, especially when combined with other modern techniques.
To implement a content-based recommender, textual features of items such as descriptions or tags are transformed into numerical vectors using TF-IDF (Term Frequency-Inverse Document Frequency). This captures the importance of words in an item relative to the whole collection. Once the items are represented as vectors, Cosine Similarity is computed to identify items that are most similar to those the user has interacted with.
Implementation using TF-IDF & Cosine Similarity
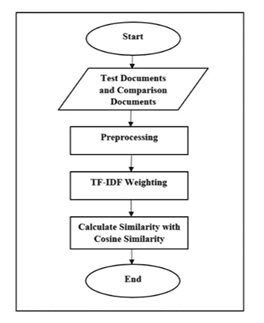
For instance, consider a small dataset of movies with descriptions. By computing TF-IDF vectors for each movie and calculating cosine similarity, the system can recommend top movies similar to Inception. The Python snippet below demonstrates this process:
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import pandas as pd movies = pd.DataFrame({ 'Movie': ['Inception','Interstellar','Avatar','The Dark Knight'], 'Description': ['dream mind-bending sci-fi','space travel time black hole', 'alien world humans sci-fi','superhero vigilante dark city'] }) tfidf = TfidfVectorizer() tfidf_matrix = tfidf.fit_transform(movies['Description']) cos_sim = cosine_similarity(tfidf_matrix) idx = 0 # Inception similar_movies = list(enumerate(cos_sim[idx])) similar_movies = sorted(similar_movies, key=lambda x: x[1], reverse=True)[1:3] for i, score in similar_movies: print(f"- {movies['Movie'][i]} (Similarity: {score:.2f})")
The output suggests Avatar and Interstellar as the closest matches to Inception, which aligns with expected user preferences. This workflow highlights how content-based systems learn from item features and provide interpretable recommendations.
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


