Your Success, Our Mission!
6000+ Careers Transformed.
In today’s digital era, where users are bombarded with endless choices, recommendation systems act as intelligent filters that simplify decision-making. They help users discover products, movies, music, and content tailored to their preferences. This chapter introduces the concept of recommendation systems, explaining how personalization has revolutionized online experiences. You’ll explore the evolution, purpose, and real-world impact of these systems before diving into the mechanics of how they actually work.
We live in an era where users expect technology to understand them. Every time you open Netflix, scroll through Instagram, or order from Zomato, invisible algorithms are quietly working to tailor what you see. This phenomenon — personalization — is powered by Recommendation Systems, one of the most successful applications of machine learning.
Personalization means delivering content, products, or services customized to an individual’s taste, behavior, and context. In data science, this is achieved by learning from user interactions, behavioral patterns, and contextual metadata.
When you rate a movie or listen to a song, you leave a data footprint.
Recommendation models capture these footprints to build a digital profile representing your preferences.
The more you interact with a platform, the smarter the system becomes, improving the accuracy of future recommendations.
| Objective | Example | Impact |
|---|---|---|
| Increase engagement | Netflix auto-suggests shows | Users spend more time on platform |
| Drive sales | Amazon recommends products | Boosts cart value |
| Retain users | Spotify curates playlists | Encourages recurring visits |
| Optimize marketing | YouTube pushes relevant ads | Improves click-through rates |
A 2023 McKinsey report revealed that 35% of Amazon’s revenue and 80% of Netflix’s watch activity come directly from recommendations — demonstrating the power of personalization at scale.
The first modern recommender, GroupLens (1994), used basic correlation techniques to suggest news articles. Over the years, recommendation systems have evolved through distinct technological waves:
| Era | Technique | Description |
|---|---|---|
| 1990–2000 | Rule-based & Collaborative | Simple “users like you” logic |
| 2006–2012 | Matrix Factorization | Netflix Prize popularized latent-factor models |
| 2013–2017 | Hybrid Models | Combined content & collaborative data |
| 2017–Present | Deep Learning & Graph Networks | Neural embeddings, attention, contextual awareness |
Today’s systems leverage embeddings, attention mechanisms, and graph neural networks to model complex human preferences.
Recommendation engines feed on diverse and heterogeneous data streams:
| Data Type | Example | Description |
|---|---|---|
| Explicit feedback | Ratings (⭐), Likes (????) | Direct expression of user preference |
| Implicit feedback | Clicks, watch time, purchase frequency | Inferred interest |
| Contextual data | Device, location, time of day | Adds situational awareness |
| Content metadata | Genre, brand, tags, price range | Describes item attributes |
| Social signals | Friends, follows, shares | Introduces peer influence |
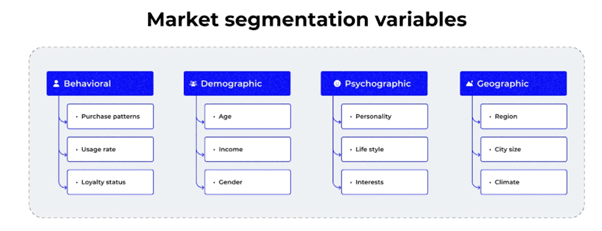
Each signal provides a unique perspective. Modern deep learning models combine them into latent representations, capturing subtle nuances of human behavior.
From Raw Data to Personalized Output
A modern recommendation pipeline typically follows five stages:
Data Collection → Gather user & item data from logs, APIs, and databases.
Feature Engineering → Clean, encode, and normalize information.
Model Training → Learn behavior patterns using collaborative, content-based, or deep learning models.
Prediction & Ranking → Generate and sort recommended items for each user.
Feedback Loop → Capture new interactions to continually refine the model.
Hands-On Mini Example
Let’s construct a small interaction log and visualize the starting point of a recommender system:
Input:
import pandas as pd # Step 1 - create simple user-history data = pd.DataFrame({ "user_id": [1, 1, 2, 2, 3, 3], "movie": ["Inception", "Matrix", "Inception", "Interstellar", "Matrix", "Avatar"], "rating": [5, 4, 5, 4, 3, 5] }) print("Sample interaction log:") print(data)
Output:
user_id movie rating 0 1 Inception 5 1 1 Matrix 4 2 2 Inception 5 3 2 Interstellar 4 4 3 Matrix 3 5 3 Avatar 5
This raw log will later be transformed into a User–Item Matrix and fed into collaborative and deep-learning models.

Every time you rate, pause, or finish a movie, Netflix updates your latent preference vector.
When a new title arrives, its embeddings are compared against your vector in high-dimensional space.
High similarity → the title surfaces on your homepage carousel, often before you consciously realize you want to watch it.
Recommendation Systems = personalization at scale
Continuously learn from behavioral and contextual data
Deep Learning enables modeling of complex, nonlinear relationships
More interactions → better personalization → higher engagement
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


