Your Success, Our Mission!
6000+ Careers Transformed.
Random Forest is a type of supervised machine learning algorithm based on ensemble learning. It is a collection of decision trees, where each tree is trained using a randomly selected subset of the data. The random forest algorithm combines multiple decision trees in order to reduce the risk of overfitting. The result is a much more accurate and stable prediction. It is one of the most popular and widely used machine learning algorithms. It can be used for both regression and classification tasks. It is also used for feature selection and to identify important variables in a dataset. It is an efficient and effective tool for complex data analysis.
Random Forest is a well-known machine learning algorithm from the supervised learning approach. It may be applied to both classification and regression issues in machine learning. It is built on the notion of ensemble learning, which is a method that involves integrating several classifiers to solve a complicated issue and enhance the model's performance.
"Random Forest is a classifier that comprises a number of decision trees on various subsets of the provided dataset and takes the average to enhance the predicted accuracy of that dataset," as the name implies. Instead of depending on a single decision tree, the random forest collects the predictions from each tree and predicts the final output based on the majority vote of predictions.
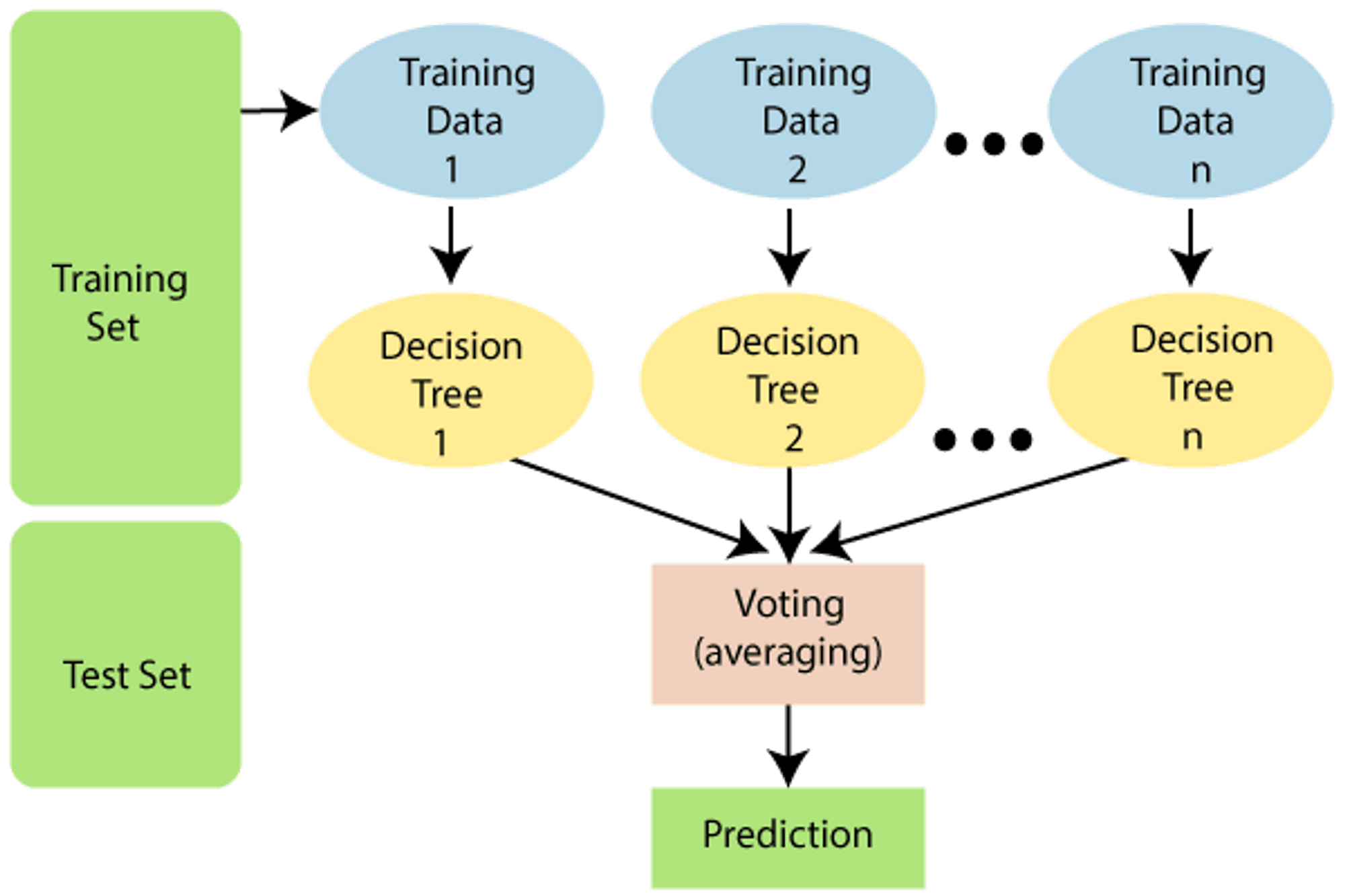
Random Forest Prediction
Because the random forest mixes numerous trees to predict the dataset's class, some decision trees may predict the proper output while others may not. But, when all of the trees are combined, they predict the proper outcome. As a result, the following are two assumptions for a better Random forest classifier:
Here are some reasons why we should utilise the Random Forest algorithm:
Random Forest operates in two stages: the first is to generate the random forest by mixing N decision trees, and the second is to make predictions for each tree generated in the first phase.
Step 1: Choose K data points at random from the training set.
Step 2: Create decision trees for the specified data points (Subsets).
Step 3: Determine the number N for the number of decision trees you wish to construct.
Step 4: Repeat Steps 1 and 2.
Step 5: Find the predictions of each decision tree for new data points and assign the new data points to the category with the most votes.
The following random forest algorithm example will help you understand how the algorithm works:
Assume there is a dataset containing several fruit photos. As a result, the Random forest classifier is given this dataset. The dataset is subdivided and distributed to each decision tree. During the training phase, each decision tree gives a prediction result, and when a new data point occurs, the Random Forest classifier predicts the final choice based on the majority of outcomes. Consider the following image:
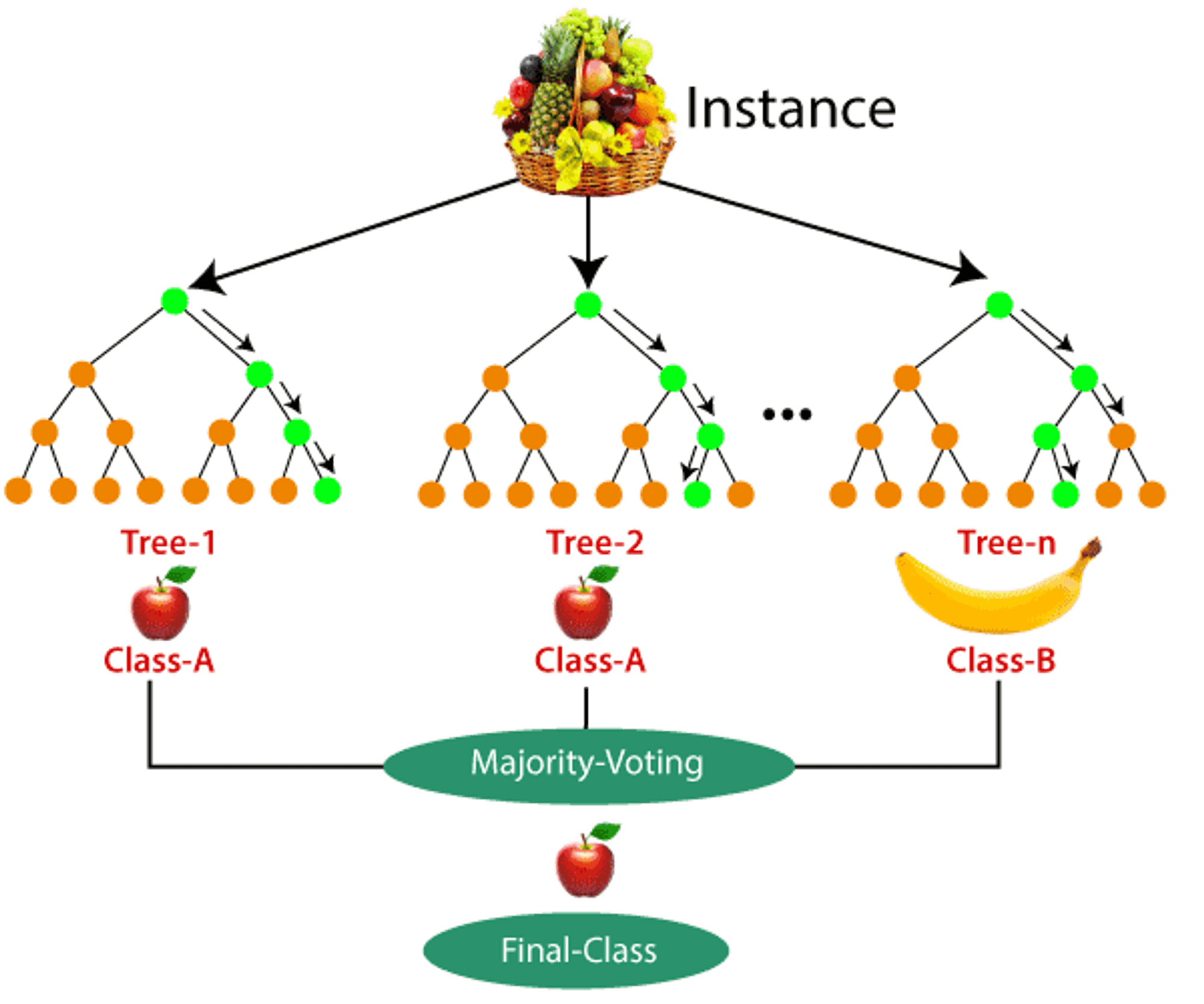
Random Forest Algorithm
Random forest algorithm is a supervised learning algorithm for classification and regression problem. It is an ensemble learning method which combines the prediction of multiple decision trees to determine the final output of the algorithm. It works by creating a forest of decision trees from randomly selected subset of training set. Each tree is grown to the largest extent possible and there is no pruning. The prediction of the individual trees are combined to determine the final output of the algorithm.
The main steps involved in the random forest algorithm are as follows:
The random forest algorithm is an efficient and powerful machine learning technique that can be used for both classification and regression tasks. It is easy to implement and can be used to solve complex problems. It is also robust to outliers, missing values, and can handle large datasets.
Lets take the following dataset for demo:
Link: https://www.kaggle.com/code/sandragracenelson/logistic-regression-on-user-data-csv
The above code is used to implement the Random Forest algorithm in Python. It begins by importing the necessary libraries such as Pandas, Numpy and the Random Forest Classifier from the sklearn library. Then the dataset is read into a Pandas DataFrame and the features and target are separated into two separate variables (X and y). Next, a Random Forest Classifier model is created and trained using the X and y variables. Finally, the model is used to predict the target variable using the features.
Random forest is an effective machine learning algorithm that can be used to build powerful models for a variety of tasks. It is a highly accurate and robust method that can handle high-dimensional data and large-scale datasets. It is also capable of handling missing values and outliers, so it is suitable for a variety of real-world applications. With its ability to generate accurate predictions, random forest is a popular choice for many data science tasks.
1.What is the main goal of using a Random Forest algorithm?
Answer: d. To predict outcomes
2. What is the main difference between a Decision Tree and a Random Forest?
Answer: c. Random Forest creates multiple Decision Trees
3.What is the benefit of using a Random Forest algorithm over a single Decision Tree?
Answer: c. It is more accurate
4.What is the main advantage of using Random Forest over other algorithms?
Answer: d. It can handle large datasets
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Applied Statistics
Master the basics of statistics with our applied statistics tutorial. Learn applied statistics techniques and concepts to enhance your data analysis skills.
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


