Your Success, Our Mission!
6000+ Careers Transformed.
Once a model is trained and ready, the next step is to make it accessible for real-world use. This chapter focuses on model serving, which is the process of delivering model predictions to applications or users efficiently and reliably. We’ll explore different serving strategies, including synchronous and asynchronous methods, and discuss considerations for scaling, latency, and reliability. By the end of this chapter, you’ll understand how serving transforms a trained model into a production-ready service.
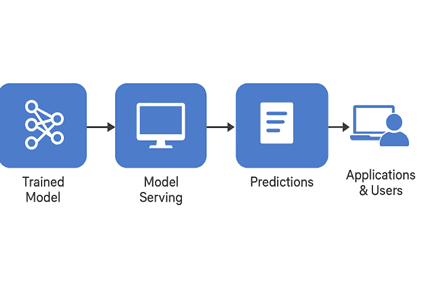
Model serving is the process of making a trained machine learning model available to provide predictions on demand. While deployment is about taking the model to production, serving ensures that the model can respond to real-time requests from users or applications efficiently.
Think of it like this:
If deployment is opening a bakery, serving is the waiter who takes the orders, delivers the dishes, and ensures the customers are satisfied.
A model might be deployed on a server, but without proper serving, requests may not be handled efficiently or reliably.
1. Real-Time Access: Applications can send input data to the model and receive predictions instantly.
2. Batch Processing: Models can handle large sets of data at once, useful for offline analysis or reporting.
3. Reliability: The system must ensure consistent predictions under varying loads.
4. Scalability: The serving infrastructure must handle increasing numbers of requests without degradation.
Example Scenario:
An e-commerce website uses a recommendation system. Each time a user visits, the model must serve recommendations in milliseconds.

A fraud detection system evaluates transactions as they happen; serving must be real-time to prevent losses.
Serving strategies can be broadly categorized as synchronous or asynchronous, depending on how predictions are requested and delivered.
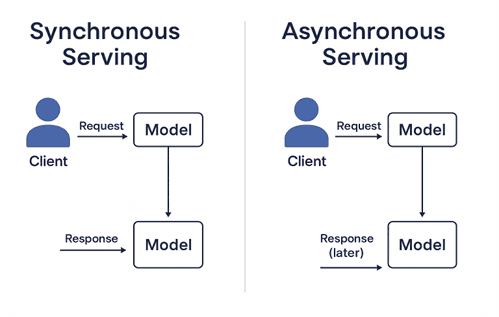
1. Synchronous Serving:
- The client sends a request and waits for the model to return a response immediately.
- Suitable for real-time applications where low latency is critical.
- Example: An online chatbot generating responses instantly.
Advantages:
- Simple to implement.
- Immediate feedback for end-users.
Challenges:
- High traffic can overload the system if not scaled properly.
- Each request blocks resources until the response is returned.
2. Asynchronous Serving:
- The client sends a request, and the model processes it in the background, returning results later.
- Suitable for batch processing or tasks where immediate results aren’t required.
- Example: Generating daily sales forecasts or processing large datasets offline.
Advantages:
- Can handle large workloads efficiently.
- Reduces system blocking and allows queuing of requests.
Challenges:
- Slightly more complex to implement.
- Users do not get immediate results.
Serving models in production requires careful planning to handle increasing traffic and maintain low latency. Key considerations include:
1. Horizontal Scaling: Adding more servers or instances to handle multiple requests concurrently.
2. Vertical Scaling: Using more powerful hardware to improve processing speed.
3. Load Balancing: Distributing incoming requests across multiple instances to avoid overload.
4. Caching: Storing frequent predictions to reduce computation and improve response times.
5. Asynchronous Queues: Using message queues to process requests in batches and avoid blocking resources.
Example:
A recommendation system on Black Friday may receive thousands of requests per second. Proper scaling ensures every user gets recommendations without delay.

Summary:
- Model serving is about making predictions available to applications or users efficiently.
- Serving strategies include synchronous (real-time, immediate response) and asynchronous (batch, delayed response).
- Scaling considerations ensure that serving remains reliable, fast, and capable of handling large workloads.
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


