Your Success, Our Mission!
6000+ Careers Transformed.
Deploying ML models in the real world comes with practical challenges. This chapter shares tips and lessons from industry practices, including handling edge cases, preparing for traffic spikes, monitoring user feedback, and collaborating across teams. By following these tips, you can ensure that your models are not only functional but also robust, scalable, and user-friendly in production.
In production, models often encounter unexpected inputs, outliers, or rare scenarios that were not present in the training data. If these cases aren’t handled properly, they can lead to errors, crashes, or unreliable predictions. Preparing for edge cases is crucial for building robust and reliable ML applications.
Key Strategies:
Validate Inputs Before Predictions:
Ensure incoming data is in the correct format and meets required constraints.
Example: If a model expects numeric input between 0–1, reject values outside this range.
Handle Missing, Malformed, or Extreme Values Gracefully:
- Replace missing values with defaults, mean/median, or imputed values.
- Handle corrupted or incomplete files without crashing the service.
Example: For a text sentiment analysis model, filter out empty or malformed text inputs instead of allowing the API to break.
Log Unusual Cases for Analysis:
- Maintain a detailed log of inputs that trigger errors or fall outside normal ranges.
- Use these logs to improve the model, retrain, or adjust preprocessing steps.
Example Scenario:
An image classifier deployed on an e-commerce platform may receive corrupted images uploaded by users. Instead of crashing, the API should return an informative error message like:
{ "error": "Invalid image format. Please upload a valid image file." }
By preparing for edge cases, you ensure your model remains robust and user-friendly, even when encountering unexpected data.
In production, your model may face sudden surges in requests due to promotions, holidays, or viral trends. Without proper planning, these spikes can slow down or crash your service. Handling traffic spikes efficiently is key for scalable and resilient deployments.
Key Strategies:
Use Load Balancers:
- Distribute incoming requests evenly across multiple servers or containers.
- Reduces the risk of overloading a single instance.
Implement Caching for Frequent Queries:
- Store results of common requests to reduce redundant computation.
- Example: Popular product recommendations can be cached and served instantly, reducing API load.
Auto-Scale Containers or Cloud Services:
- Configure your deployment to automatically increase the number of active containers during high demand.
- Example: On Black Friday, a recommendation engine should scale up to handle thousands of requests per second, then scale down afterward to save costs.
Additional Tips:
- Monitor server CPU, memory, and API latency to detect load issues early.
- Use cloud provider tools like AWS Auto Scaling, GCP Cloud Run, or Azure Scale Sets.
- By planning for spikes, your model remains reliable, fast, and cost-efficient, even under extreme demand.
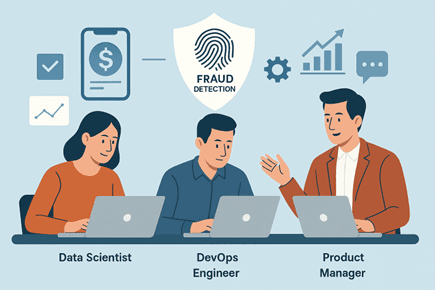
Deploying ML models is rarely a solo effort. Collaboration between data scientists, ML engineers, DevOps, and product teams is critical for smooth deployment and long-term success.
Key Practices:
Effective Communication:
- Regular updates between teams ensure everyone is aligned on deployment timelines, model changes, and requirements.
Example: Data scientists can explain model assumptions while DevOps plans infrastructure accordingly.
Clear Documentation:
- Document API endpoints, input/output formats, model versions, and deployment pipelines.
- Helps new team members understand the system quickly and reduces errors.
Shared Monitoring Dashboards:
- Create dashboards that display model performance, API latency, error rates, and usage patterns.
- Keeps stakeholders informed and allows proactive troubleshooting.
Example Scenario:
A fraud detection system deployed across a banking app requires coordination:
- Data scientists monitor model accuracy.
- DevOps handles deployment and scaling.
- Product managers track system performance and user feedback.
By fostering collaboration and communication, the team can quickly identify issues, roll out updates, and maintain a high-quality service.
Summary :
- Follow best practices for version control, monitoring, and CI/CD.
- Continuously maintain models to handle data drift and performance degradation.
- Ensure security, privacy, and compliance in production.
- Prepare for edge cases, traffic spikes, and collaborate effectively across teams.
- Applying these practices ensures models remain robust, scalable, and reliable in real-world deployment.
Deploying machine learning models is more than just training and testing—they must be accessible, scalable, reliable, and secure to create real-world impact. Through this tutorial, we’ve explored:
- Foundations of model deployment and serving
- Different deployment architectures including on-premise, cloud, microservices, and serverless
- Popular tools and frameworks like Flask, FastAPI, Docker, and cloud platforms
- Hands-on deployment steps including model preparation, API building, containerization, and monitoring
- Best practices, MLOps principles, and real-world tips to maintain model performance and reliability
By combining theory with hands-on practices, you now have the practical knowledge to deploy models confidently in production environments.
Machine learning deployment is a journey—one that requires continuous learning, monitoring, and iteration. With these skills, you can turn trained models into production-ready solutions that drive real business value.
If you want to master ML deployment end-to-end and gain practical, industry-relevant skills, join AlmaBetter’s Data Science and AI programs. With hands-on projects, expert guidance, and a structured curriculum, AlmaBetter helps you build a career in AI and ML by taking you from training models to deploying them in production.
Start your journey with AlmaBetter today and become a deployment-ready ML practitioner!
Challenges in ML Model Development and Deployment — AlmaBetter Bytes article covering common obstacles in deploying ML models.
Key Principles of MLOps (Machine Learning Operations) — Deep dive into MLOps practices, which are critical for model deployment and serving.
CI/CD for Machine Learning — Focuses on automation, deployment pipelines and how to maintain ML models in production.
Best Practices for Containerization of ML Applications — A detailed look at containerizing ML applications (which is central to deployment).
10 Most Popular Data Science Tools to Use (Best in 2025) — Includes tools relevant to deployment (e.g., Docker, Kubernetes, cloud services).
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


