

Data Science
Data Manipulation Techniques in Python Programming Language
Last Updated: 3rd September, 2023

Narender Ravulakollu
Technical Content Writer at almaBetter
Master data manipulation techniques in Python with valuable tips for efficient data handling. Learn essential methods and best practices. Level up your skills.

Data manipulation is the backbone of data analysis and machine learning. It involves a set of essential techniques to cleanse, reshape, and transform raw data into a more usable form.
In this blog, we'll explore the top five Tips for data manipulation techniques that are crucial for any data practitioner. Using Python's powerful libraries like Pandas and SQL, we'll learn how to handle missing values, aggregate data, filter information, and more.
Let's dive in and unlock the true potential of data manipulation techniques in python for insightful analysis and decision-making!
List of Techniques
Data Cleaning: Identifying Missing Values and Removing Duplicates
In the world of data analysis, ensuring data quality is paramount. Data cleaning plays a vital role in this process, helping us identify and handle missing values and eliminate duplicate records. Let's explore how to achieve this using Python's Pandas library.
Identifying Missing Values:
Missing data can wreak havoc on our analysis, leading to inaccurate insights. With Pandas, we can easily detect missing values in our dataset and decide how to handle them. The `isnull()` and `notnull()` functions let us identify and filter out the missing entries. Various techniques like imputation or removal can be employed based on the nature of the data.
Removing Duplicate Records:
Duplicate entries can skew our analysis and misrepresent the true distribution of the data. Pandas' `duplicated()` and `drop_duplicates()` methods come to our rescue here. We can check for duplicate rows and eliminate them from the dataset, ensuring the integrity of our analysis.
Implementation:
Let's demonstrate the data cleaning process using Pandas:

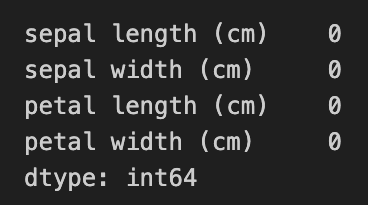
By utilizing these data cleaning techniques, we can ensure our dataset is free from errors, enabling us to draw accurate conclusions and make informed decisions based on reliable data. Python's Pandas library provides a robust and user-friendly environment for efficient data cleaning, setting the stage for successful data analysis endeavors.
Data Transformation: Reshaping Data and Converting Data Types
Data transformation is a critical step in data manipulation techniques in python, allowing us to reshape our data for better analysis and convert data types to facilitate meaningful computations. We'll explore two essential data transformation techniques: reshaping data using melting and pivoting, and converting data types using Pandas and NumPy.
Reshaping Data - Melting and Pivoting:
Reshaping data involves converting data from one format to another. Two common operations are melting and pivoting.
Melting is the process of transforming a dataset from a wide format to a long format. It involves converting columns into rows, which can be useful when dealing with multi-variable datasets.
Pivoting, on the other hand, converts data from a long format to a wide format, essentially undoing the melting process. It allows us to reorganize our data, making it easier to understand and analyze.
Converting Data Types:
Data may arrive in different formats, and converting data types is crucial to ensure consistency and perform computations accurately. For example, converting string data to numerical values or converting categorical data to numeric codes.
Implementation:
Let's demonstrate data transformation using Pandas and NumPy:
import pandas as pd
import numpy as np
# Sample dataset
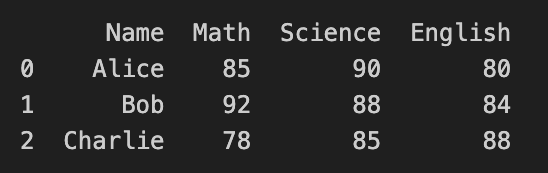
data = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Math': [85, 92, 78],
'Science': [90, 88, 85],
'English': [80, 84, 88]
})
print(data)
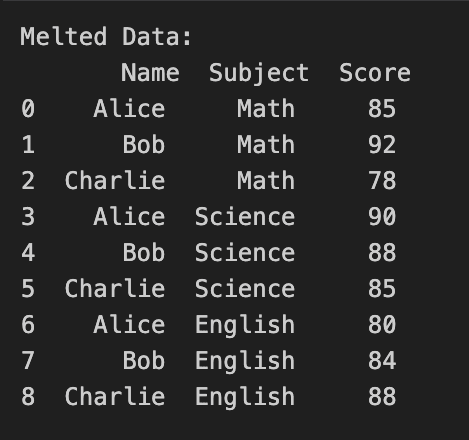
# Reshaping data - Melting
melted_data = pd.melt(data, id_vars='Name', var_name='Subject', value_name='Score')
print("Melted Data:\n", melted_data)
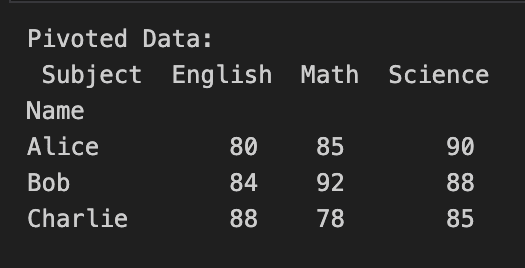
# Pivoting data
pivoted_data = melted_data.pivot(index='Name', columns='Subject', values='Score')
print("Pivoted Data:\n", pivoted_data)
# Converting data types
data['Math'] = data['Math'].astype(float)
data['Science'] = data['Science'].astype(np.float64)
data['English'] = pd.to_numeric(data['English'])
print("Converted Data Types:\n", data.dtypes)
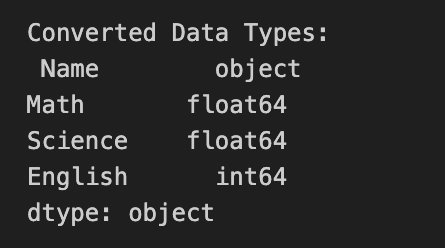
In this example, we have a sample dataset with student names and their scores in different subjects. We first demonstrate data reshaping by melting the dataset using the `pd.melt()` function and then pivoting it back to the original format with the `pivot()` method.
Next, we convert the data types of the 'Math', 'Science', and 'English' columns to float using different approaches such as `.astype()` and `pd.to_numeric()`.
Data transformation is a powerful tool to reshape and manipulate data, making it more suitable for analysis and modeling. By leveraging Pandas and NumPy, we can efficiently handle data transformation tasks and prepare our data for advanced data analysis and machine learning processes.
Data Aggregation: Summarizing Data and Grouping
Data aggregation is a vital process for deriving valuable insights from datasets. We'll explore two primary data aggregation techniques: summarizing data with descriptive statistics and grouping data based on specific criteria using Pandas.
Summarizing Data with Descriptive Statistics:
Descriptive statistics, such as mean, median, standard deviation, minimum, maximum, and percentiles, help us understand the central tendency and distribution of data. Pandas provides convenient methods to compute these statistics.
Grouping Data Based on Specific Criteria:
Grouping data allows us to analyze subsets based on specific attributes or conditions. For instance, we can group data by a categorical variable and then perform aggregations on each group, gaining insights into different segments of the data.
Implementation with Pandas:
Let's demonstrate data aggregation using Pandas:
import pandas as pd
# Sample dataset
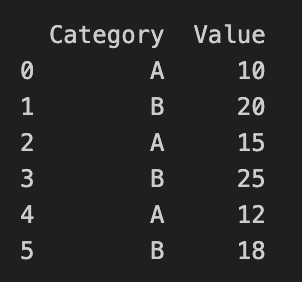
data = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18]
})
print(data)
# Summarizing data with descriptive statistics
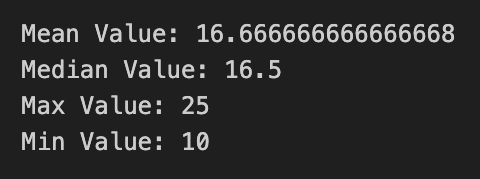
mean_value = data['Value'].mean()
median_value = data['Value'].median()
max_value = data['Value'].max()
min_value = data['Value'].min()
print("Mean Value:", mean_value)
print("Median Value:", median_value)
print("Max Value:", max_value)
print("Min Value:", min_value)
# Grouping data based on specific criteria
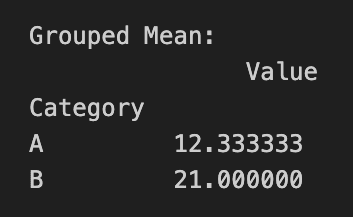
grouped_data = data.groupby('Category')
grouped_mean = grouped_data.mean()
grouped_sum = grouped_data.sum()
print("Grouped Mean:\n", grouped_mean)
print("Grouped Sum:\n", grouped_sum)
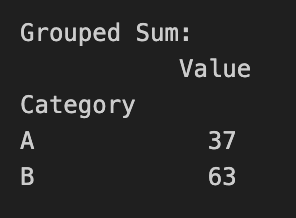
Data aggregation is a fundamental step in data analysis, helping us uncover patterns, trends, and relationships within complex datasets. By mastering these techniques with Pandas, data practitioners can efficiently extract valuable information from their data.
Data Filtering: Applying Conditions to Filter Data
Data filtering is an essential technique for extracting specific subsets of data based on conditions. With Pandas, we can easily filter data using logical operators, enabling us to perform both simple and complex filtering operations.
Applying Conditions to Filter Data:
To filter data, we apply conditions on one or more columns. The conditions can involve comparison operators like equal to (`==`), not equal to (`!=`), greater than (`>`), less than (`<`), etc. We can also combine multiple conditions using logical operators like `and` and `or`.
Implementation with Pandas:
Let's demonstrate data filtering using Pandas:
import pandas as pd
# Sample dataset
data = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Ella'],
'Age': [25, 30, 22, 28, 35],
'Score': [85, 90, 78, 92, 80]
})
print(data)
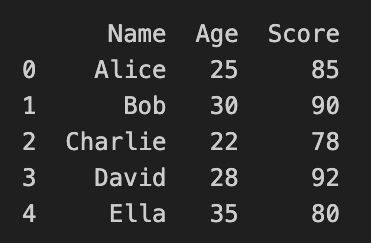
# Applying conditions to filter data
# Example: Filter for individuals with Age greater than 25 and Score greater than or equal to 80
filtered_data = data[(data['Age'] > 25) & (data['Score'] >= 80)]
print("Filtered Data:\n", filtered_data)
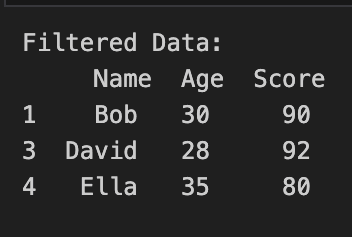
In this example, we have a sample dataset with columns 'Name', 'Age', and 'Score'. We use Pandas to filter the data based on the condition where 'Age' is greater than 25 and 'Score' is greater than or equal to 80. The result is a subset of the original data containing only the rows that meet the specified criteria.
Data filtering is a powerful tool for extracting meaningful subsets of data, allowing us to focus on specific observations that are relevant to our analysis. With Pandas' intuitive syntax, data practitioners can efficiently perform filtering operations to uncover valuable patterns and insights from their datasets.
Conclusion
In the realm of data analysis, data manipulation techniques serve as the backbone of every successful project. Throughout this blog, we explored the top five essential data manipulation techniques that every data practitioner should master. To delve deeper into this subject, explore our enticing data science course, which offers a unique pay after placement opportunity. Alternatively, embark on your educational journey with our data science tutorial. We're here to empower your learning experience.
Related Articles
Top Tutorials

Made with in Bengaluru, India









- Join AlmaBetter
- Sign Up
- Become an Affiliate
- Become A Coach
- Coach Login
- Policies
- Privacy Statement
- Terms of Use
- Contact Us
- admissions@almabetter.com
- 08046008400
- Official Address
- 4th floor, 133/2, Janardhan Towers, Residency Road, Bengaluru, Karnataka, 560025
- Communication Address
- Follow Us

© 2025 AlmaBetter