Your Success, Our Mission!
6000+ Careers Transformed.
Gradient Boosting is an ensemble learning technique that combines multiple weak learners to form a strong learner. It is a powerful technique for both classification and regression tasks. Commonly used gradient boosting algorithms include XGBoost, LightGBM, and CatBoost. Each algorithm uses different techniques to optimize the model performance such as regularization, tree pruning, feature importance, and so on.
What is Gradient Boosting
Gradient Boosting is a prominent technique for boosting. In gradient boosting, each prediction corrects the inaccuracy of its previous. Unlike Adaboost, the weights of the training instances are not changed; instead, each predictor is trained using the predecessor's residual mistakes as labels.
Gradient Boosted Trees is a method whose basic learner is CART (Classification and Regression Trees).
The graphic below illustrates how gradient boosted trees are trained for regression situations.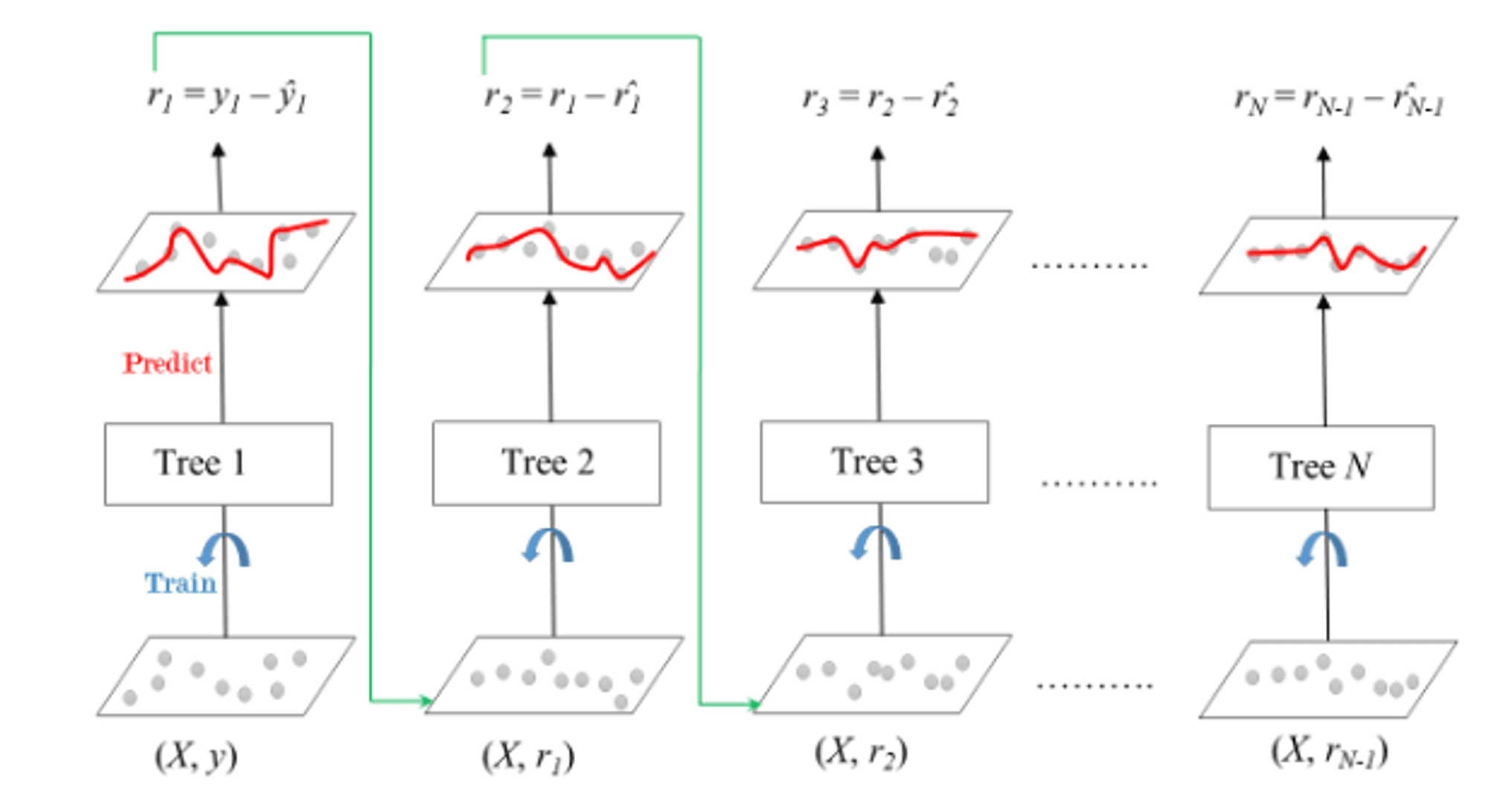
The ensemble is made up of N trees. The feature matrix X and the labels y are used to train Tree1. The y1(hat) predictions are utilised to calculate the training set residual errors r1. Tree2 is then trained with Tree1's feature matrix X and residual errors r1 as labels. The projected r1(hat) values are then utilised to calculate the residual r2. The technique is continued until all N trees in the ensemble have been trained.
This approach employs an essential parameter called as shrinkage.
Shrinkage refers to the fact that after multiplying the prediction of each tree in the ensemble by the learning rate (eta), which varies from 0 to 1, the forecast of each tree in the ensemble is shrunk. There is a trade-off between eta and the number of estimators; a decrease in learning rate must be compensated by an increase in estimators in order to achieve a specific level of model performance. Predictions may now be made because all trees have been taught. Each tree predicts a label, and the formula provides the final forecast.
y(pred) = y1 + (eta * r1) + (eta * r2) + ....... + (eta * rN)
GradientBoostingRegressor is the Scikit-Learn class for gradient boosting regression. GradientBoostingClassifier is a classification algorithm that uses a similar approach.
How does gradient descent works?
The basic idea behind gradient descent is to iteratively adjust the model parameters in the direction of steepest descent of the cost function until the minimum is reached.
Here is a step-by-step explanation of how gradient descent works:
The size of the step taken at each iteration is called the learning rate. A high learning rate can cause the algorithm to overshoot the minimum and bounce back and forth, while a low learning rate can cause the algorithm to converge slowly.
There are variations of gradient descent, such as stochastic gradient descent and mini-batch gradient descent, which use random subsets of the training data to compute the gradient at each iteration. These methods can be more efficient for large datasets.
Python implementation
Lets use boston dataset for the demo
Use the already available dataset boston which is in sklearn
import the dataset as “from sklearn.datasets import load_boston”
The Boston housing dataset is included in the Scikit-Learn library. It can be accessed by importing the dataset from the sklearn.datasets module. The dataset contains 506 samples and 13 features. It can be used for both regression and classification tasks. It is a great dataset for practicing machine learning techniques, such as gradient boosting.
This code uses the Gradient Boosting Regressor model from the scikit-learn library to predict the median house prices in the Boston Housing dataset. First, it imports the necessary libraries for the code. Then, it loads the Boston Housing dataset from the scikit-learn library. Next, it splits the data into train and test sets. After that, it creates the Gradient Boosting Regressor model, fits it to the training data, and uses it to make predictions on the test data. Finally, it calculates the mean squared error and R2 score on the test data and prints the results.
Conclusion
Gradient Boosting is a powerful and popular ensemble learning technique for both classification and regression tasks. It combines multiple weak learners into a single strong learner by sequentially optimizing the model performance. Commonly used gradient boosting algorithms include XGBoost, LightGBM, and CatBoost. Hyperparameter tuning and loss functions are important considerations when training gradient boosting models. Feature selection, model interpretation, and model ensembling techniques can also be used to improve the model performance. Gradient Boosting is a powerful technique and can be used to achieve excellent results on a variety of tasks.
Key takeaways
Quiz
1.Which of the following is an important step in training gradient boosting models?
Answer: B. Feature Selection
2.What metric is commonly used for evaluating the performance of a gradient boosting model?
Answer: D. Mean Squared Error
3.Which of the following is a commonly used technique for handling imbalanced data with gradient boosting?
Answer: A. Oversampling
4.What is the name of the popular library for training and deploying gradient boosting models?
Answer: D. All of the Above
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Applied Statistics
Master the basics of statistics with our applied statistics tutorial. Learn applied statistics techniques and concepts to enhance your data analysis skills.
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


