Your Success, Our Mission!
6000+ Careers Transformed.
Overview
Support Vector Machines (SVMs) are a capable and well known machine learning procedure utilized for classification and regression errands. SVMs are a supervised learning algorithm that can be utilized to classify information into two or more classes. They are also able to recognize non-linear designs and make decisions based on complex data. SVMs are based on the concept of maximizing the margin (or distance) between different classes of data points. SVMs utilize bit capacities to outline information into a better dimensional space in order to develop a decision boundary that can partition the information into two or more classes. SVMs are effective in high dimensional spaces and can be utilized for an assortment of errands, such as image classification, text classification, and bioinformatics.
Introduction to SVM
There was a little trade that had a really imperative errand to achieve. They required to precisely decide whether or not a client was likely to purchase their items. In the event that they might precisely foresee this, at that point they may target their promoting endeavors and increment their deals. The trade chosen to use an algorithm called Support Vector Machines (SVMs) to assist them. SVMs are powerful classification algorithms that take information around the clients and employs it to make a model that can precisely foresee whether or not a client is likely to purchase an item. The company fed their information into the SVM algorithm and it rapidly made a model that precisely distinguished which clients were likely to purchase and which were not. The company at that point utilized this model to target their promoting endeavors and finished up seeing a noteworthy increment in deals as a result.
Support Vector Machines (SVMs) are a type of supervised machine learning algorithm that can be utilized for both classification and regression errands. It is a capable and flexible algorithm utilized for both linear and non-linear data sets. SVMs are based on the idea of finding a hyperplane that best separates two classes. The best hyperplane is the one that has the maximum margin, which means the maximum distance between data points of both classes.
Advantages of SVMs include the ability to handle both linear and non-linear data, the ability to be used in high-dimensional spaces, and the ability to use kernels to create non-linear decision boundaries.
Disadvantages of SVMs include high computational cost when training, the risk of overfitting, and the need for careful tuning of the model's parameters.
SVM kernel functions
SVM kernel functions are mathematical functions that are used by support vector machines (SVMs) to define a decision boundary between data points. They are used to transform the input data into a higher dimensional space and then classify the data into two or more classes. Some of the most popular SVM kernel functions are:
1. Linear Kernel Polynomial Kernel RBF Kernel/ Radial Kernel
2. Sigmoid Kernel
Linear Kernel
Commonly recommended for text classification because most of these types of classification problems are linearly separable. The linear kernel is the simplest kernel function. It is used when the data is linearly separable. Linear kernel works really well when there are a lot of features.
Linear kernel functions are faster than most of the others and have fewer parameters to optimize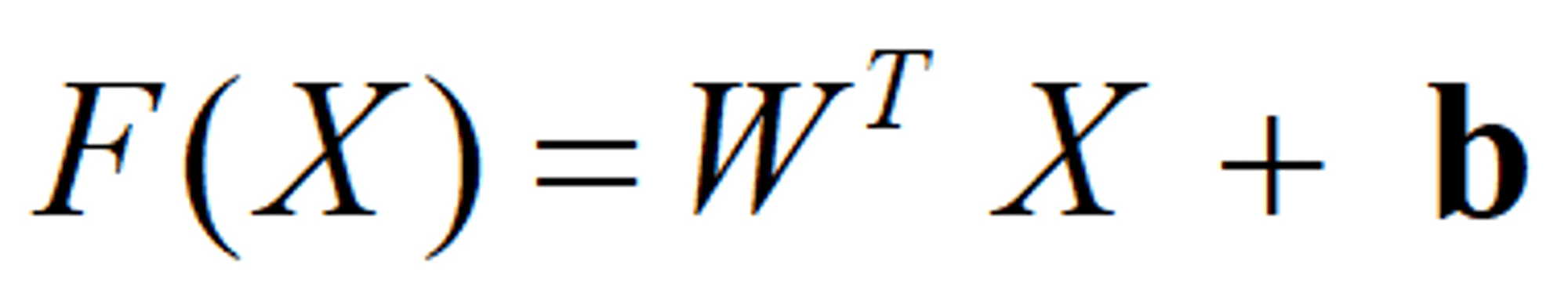
W is the weight vector that you want to minimize, X is the data that you're trying to classify, and b is the linear coefficient estimated from the training data.
Polynomial Kernel
The polynomial kernel is used when the data is not linearly separable. The polynomial kernel isn't used in practice very often because it isn't as computationally efficient as other kernels and its predictions aren't as accurate.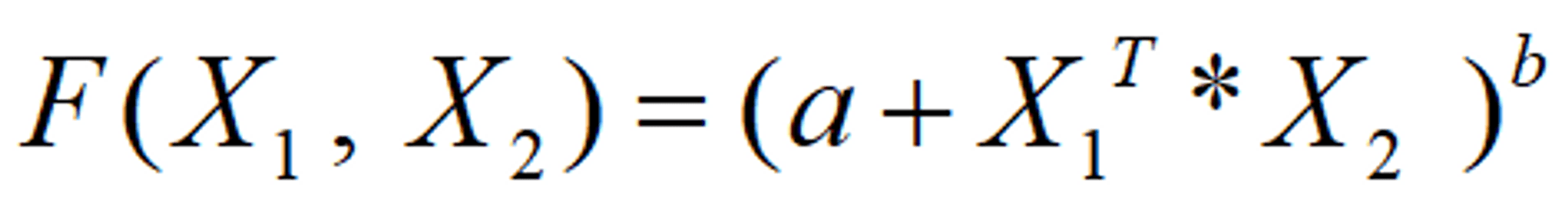
f(X1, X2) represents the polynomial decision boundary that will separate your data. X1 and X2 represent your data.
Gaussian Radial Basis Kernel (RBF):
The Radial Basis Function (RBF) kernel is a kernel function used in support vector machines (SVMs). The RBF kernel is used when the data is not linearly separable and has a non-linear decision boundary. One of the most powerful and commonly used kernels in SVMs. Usually the choice for non-linear data.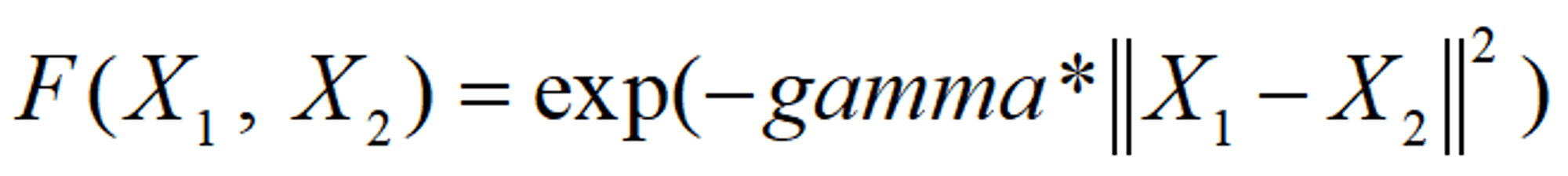
Sigmoid Kernel
The Sigmoid kernel is a kernel function used in support vector machines (SVMs). It is used when the data has a non-linear decision boundary. The Sigmoid kernel is calculated by taking the logistic function of the dot product of two data points. The logistic function is used to transform a linear combination of inputs into a value between 0 and 1. The Sigmoid kernel can be seen as a generalization of the linear kernel, as it allows for non-linear decision boundaries. The Sigmoid kernel is often used in machine learning tasks such as classification and regression. More useful in neural networks than in support vector machines
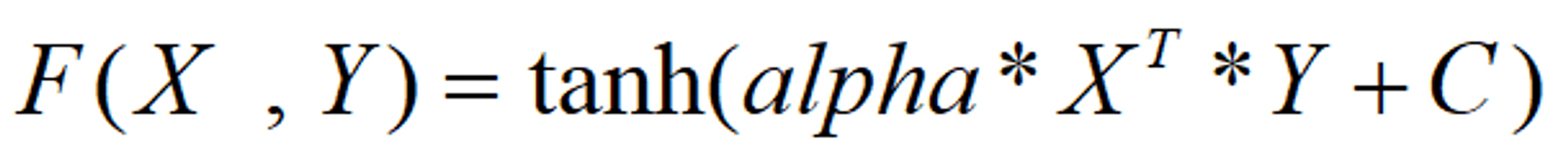
In this function, alpha is a weight vector and C is an offset value to account for some miss-classification of data that can happen.
How to choose the right one for a particular problem
The choice of the kernel function depends on the nature of the problem. For example, if the data points are linearly separable, then a linear kernel should be used. If the data points are not linearly separable, then a non-linear kernel such as a polynomial, RBF, or sigmoid kernel should be used. The parameters of the kernel function (e.g., c, d, α, σ) also need to be tuned to get the best results.
When selecting a kernel, it is important to consider the type of data that the problem is dealing with. For instance, a radial basis function (RBF) kernel may be more appropriate for image or time series data, while a polynomial kernel may be more suitable for classification problems. Furthermore, the choice of kernel may also depend on the specific algorithm being used to solve the problem.
In addition, it is important to consider the computational complexity of the chosen kernel. Some kernels are computationally more expensive than others and may require more resources to train a machine learning model. It is also important to ensure that the chosen kernel is suitable for the available data. For example, a kernel may be unsuitable for sparse data.
Finally, it is important to consider the model performance when selecting a kernel. Different kernels may yield different levels of accuracy, precision, recall, and other model metrics. After selecting a kernel, it is important to tune the parameters of the kernel to achieve the best possible performance.
Tuning SVM parameters
The regularization parameter C is used to control the trade-off between the fitting of the data and the complexity of the model. A large C value will result in a model that fits the data closely, while a small C value will result in a model that is more generalizable and robust.
The kernel parameter gamma is used to control the non-linearity of the model. A large gamma value will result in a model with more complex non-linearities, while a small gamma value will result in a model with fewer non-linearities.
In general, the values for C and gamma should be chosen to maximize the accuracy of the model on the validation data. This can be done by using a grid search approach to find the parameters that result in the best model performance. This involves creating a grid of various parameter combinations and evaluating the performance of the model on the validation data for each combination. The combination which produces the best performance metrics can then be chosen as the optimal parameters.
Multi-class SVM
Multi-class SVM is a method used to extend the SVM algorithm to handle multi-class classification problems. It can be used to classify data with more than two classes. The two most common approaches are one-vs-all and one-vs-one.
The one-vs-all approach involves training multiple binary classifiers, each of which is trained to distinguish one of the classes from all of the other classes. For example, if we are trying to classify a dataset with three classes (A, B and C), we would train three binary classifiers, each of which would be trained to distinguish one of the classes (A, B and C) from the other two classes. The final classification decision would be based on the classifier that achieved the highest score.
The one-vs-one approach involves training multiple binary classifiers, each of which is trained to distinguish one of the classes from one other class. For example, if we are trying to classify a dataset with three classes (A, B and C), we would train three binary classifiers, each of which would be trained to distinguish one of the classes (A, B and C) from one other class. The final classification decision would be based on the classifier that achieved the highest score among all of the classifiers.
Both of these approaches are used to extend the SVM algorithm to multi-class classification problems. They both involve training multiple binary classifiers, but the one-vs-all approach is simpler and easier to implement, while the one-vs-one approach is more accurate.
SVM for regression
Support Vector Machines (SVMs) are supervised machine learning algorithms used for both classification and regression problems. In regression problems, SVMs are used to identify the relationship between a dependent variable (target) and a set of independent features (predictors). They can be used for linear and non-linear regression problems, where the kernel function can be chosen to fit the data. The objective of a SVM for regression is to find the optimal hyperplane that best separates the data points of different target values. This hyperplane is then used to make predictions for new data points.
SVM for classification
Support Vector Machines (SVMs) are supervised learning algorithms commonly used for classification. SVMs use a combination of linear and non-linear techniques to classify data by constructing a hyperplane that maximizes the margin between the two classes. This allows SVMs to classify data with a high degree of accuracy, even when the data is highly complex and non-linear.
SVM implementation
Lets consider the titanic.csv for the example implementation of svm in python
Link: https://www.kaggle.com/c/titanic
This code is a Python implementation of the Support Vector Machine (SVM) algorithm for the Titanic dataset. The code starts by importing the necessary libraries, such as pandas, numpy, and sklearn's SVC module. Then, the Titanic dataset is loaded. The data is then separated into features (X) and target (y). The data is then split into training and testing sets using the train_test_split function. The SVM model is then created and trained using the fit function. The model is evaluated by getting the accuracy score and confusion matrix. Finally, the model is used to make predictions on the test set.
SVM limitations
1. SVM is inclined to over-fitting: SVM may be a effective machine learning algorithm that can classify complex data points with high accuracy. In any case, it is inclined to over-fitting when the information set is little or the number of features is too huge.
2. Restricted to two-class classification issues: SVM is constrained to two-class classification issues, meaning that it cannot be utilized for multi-class classification issues.
3. Not reasonable for huge data sets: SVMs are not reasonable for huge data sets since they require a lot of memory and computational power. It is additionally troublesome to scale SVMs to huge information sets.
4. Sensitive to outliers: SVMs are delicate to outliers, meaning that a single outlier can altogether affect the performance of the model.
5. Time-consuming: SVM could be a time-consuming algorithm because it usually takes a long time to train the model and test the comes about.
SVM extensions
Support Vector Regression (SVR): SVR is an extension of the SVM model used for regression tasks. It uses the same principles as SVM for classification, with the added capability to fit a continuous function to data. SVR is a non-linear regression technique used to predict continuous values from given data points. The objective of SVR is to minimize the error between the predicted values and the actual values of the data points. The problem is posed as an optimization problem, where the objective is to minimize the following cost function:
C∗ = 1N∑i=1N (yi −f(xi))2 + λ||w||2
Where C* is the cost function, N is the number of data points, yi is the actual value of the data point, f(xi) is the predicted value of the data point, λ is a regularization parameter, and ||w||2 is the squared norm of the weights vector of the model.
Support Vector Clustering (SVC): SVC is a clustering technique that uses the same principles as SVM for classification. It is used to group data points into clusters based on their similarity, and it is often used in unsupervised learning. The objective of SVC is to minimize the following objective function:
C∗ = ∑i,j=1N(xi −xj)2K(xi,xj)
Where C* is the cost function, N is the number of data points, xi is the data point, and K(xi,xj) is the kernel function which measures the similarity between two data points.
Online SVM: Online SVM is an extension of the SVM model used for online learning. It is used to update the model on a continuous basis as new data points are received. The objective of Online SVM is to minimize the following objective function:
C∗ = ∑i=1N(yi −f(xi))2 + λ||w||2
Where C* is the cost function, N is the number of data points, yi is the actual value of the data point, f(xi) is the predicted value of the data point, λ is a regularization parameter, and ||w||2 is the squared norm of the weights vector of the model.
Conclusion
The business was able to successfully use an SVM algorithm to accurately predict which customers were likely to buy their products. This allowed them to target their marketing efforts more effectively and increase their sales. The business was very pleased with the results and continues to use SVMs to accurately identify their customer base and target their marketing efforts.
Key takeaways
Quiz
1.What type of problems can be solved using Support Vector Machines?
Answer: D. All of the above
2. What type of kernel is commonly used in SVM?
Answer: B. Radial Basis Function
3. What are the two main tasks in SVM?
Answer: B. Classification and Regression
4.What is the primary goal of a Support Vector Machine?
Answer: C. To maximize the margin between data points
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Applied Statistics
Master the basics of statistics with our applied statistics tutorial. Learn applied statistics techniques and concepts to enhance your data analysis skills.
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


