Your Success, Our Mission!
6000+ Careers Transformed.
Imagine It’s 8 AM. You’re sipping your coffee and your phone buzzes.
“ Congratulations! You’ve won a FREE iPhone! Click here to claim your prize!”
You roll your eyes.
But then another text arrives:
“Your Amazon order #4567 has been shipped.”
Now that’s a useful one!
How did your phone instantly recognize which message is spam and which is real?
That’s the magic of Machine Learning and Natural Language Processing (NLP) quietly protecting you from junk every single day.

The idea is simple but genius:
You teach your computer to read text messages, analyze patterns, and classify them into two buckets:
To do that, your ML model must learn the language of humans — not in emotions, but in patterns of words.
For example:
| Spam Words | Legit Words |
|---|---|
| Win | Meeting |
| Prize | Invoice |
| Click | Delivery |
| Free | Report |
Over thousands of messages, your model starts to see the difference just like your brain does subconsciously.
Let’s break it down like a detective case
We feed the model a dataset containing thousands of messages each labeled as Spam or Ham.
Example:
| Message | Label |
|---|---|
| “Claim your free coupon now!” | Spam |
| “Hey, are we meeting today?” | Ham |
This is how the model starts learning what’s normal vs. suspicious.
Before teaching the model, we tidy up the text:
This step ensures the model focuses only on the important words.
Now the magic trick is to turn words into numbers.
Using methods like TF-IDF (Term Frequency–Inverse Document Frequency), we measure how important a word is in the message.
For example, if “free” appears in many spam messages but rarely in normal texts it becomes a powerful spam indicator!
Once the text is converted into numerical form, we feed it to a Machine Learning Algorithm most often Naive Bayes or Logistic Regression.
The model studies the data, recognizing subtle patterns like:
“If a message contains 3 or more exclamation marks + the word ‘win’ → high chance of spam!”
Now comes the exciting part testing your model with unseen messages.
Example:
“Win a free vacation now!” → Spam
“Lunch at 1 PM?” → Ham
If it correctly classifies most of them, your spam detector is officially smart!
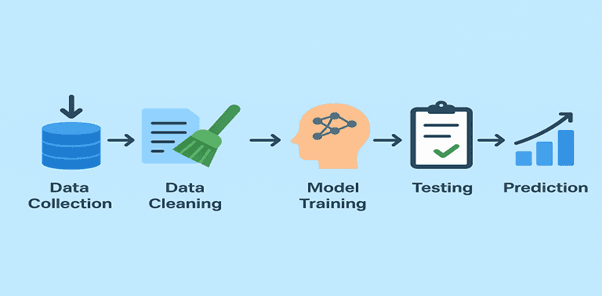
Here’s a simple way to build your own SMS Spam Detector.
# Step 1: Import libraries import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score, classification_report # Step 2: Load dataset data = pd.read_csv("spam.csv", encoding='latin-1')[['v1', 'v2']] data.columns = ['label', 'message'] # Step 3: Preprocess data vectorizer = TfidfVectorizer(stop_words='english') X = vectorizer.fit_transform(data['message']) y = data['label'].map({'ham': 0, 'spam': 1}) # Step 4: Split and train model X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) model = MultinomialNB() model.fit(X_train, y_train) # Step 5: Predict and evaluate preds = model.predict(X_test) print("Accuracy:", round(accuracy_score(y_test, preds) * 100, 2), "%") print("\nReport:\n", classification_report(y_test, preds))
Expected Accuracy: ~97–99%!
Your model is officially better than most humans at spotting spam
Spam detection isn’t just about texts it’s everywhere!
Once you build the basic model, try to improve it:
Top Tutorials

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career

MLOps
Dive into the fundamentals with our MLOPs tutorial. Learn MLOps best practices and streamline your ML operations for enhanced productivity and reliability.

ChatGPT
In this ChatGPT tutorial, learn how to use ChatGPT effectively. Master the art of conversational AI with our step-by-step lessons. Start to learn ChatGPT today!
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


